Bagaimana AI Kami Mendengarkan Anak Anda Membaca Bahasa Arab — dan Memperbaiki Pengucapan secara Real Time
Amal menggunakan pengenalan suara AI dua lapis — menggabungkan speech-to-text (STT) pada perangkat untuk umpan balik instan dengan Google Cloud Speech-to-Text untuk penilaian pengucapan yang lebih akurat. Sistem ini dirancang khusus untuk suara anak yang membaca bahasa Arab, termasuk kesadaran penuh tanda diakritik (tashkeel). Tidak ada aplikasi pembelajaran bahasa Arab lain yang memberikan koreksi pengucapan real-time untuk anak-anak.
Masalah yang Kami Selesaikan
Arab memiliki 28 huruf tetapi lebih dari 100 bunyi jika menghitung tanda diakritik (fatha, damma, kasra, shadda, sukun, tanween). Suara anak berbeda secara akustik dari orang dewasa — nada lebih tinggi, artikulasi kurang, dan volume variatif. Model speech-to-text yang ada, bahkan yang canggih seperti Google, tidak dilatih pada anak-anak yang membaca Arab dengan tanda diakritik lengkap.
Kebanyakan aplikasi melewatkan umpan balik pengucapan atau menggunakan pencocokan gelombang suara sederhana yang menghukum aksen dan variasi alami. Pendekatan itu tidak cocok bagi anak-anak yang belajar bahasa dengan bunyi yang tidak ada dalam bahasa Inggris.
Cara Kerja: Arsitektur STT Ganda
Sistem kami menjalankan dua jalur pengenalan suara secara bersamaan:
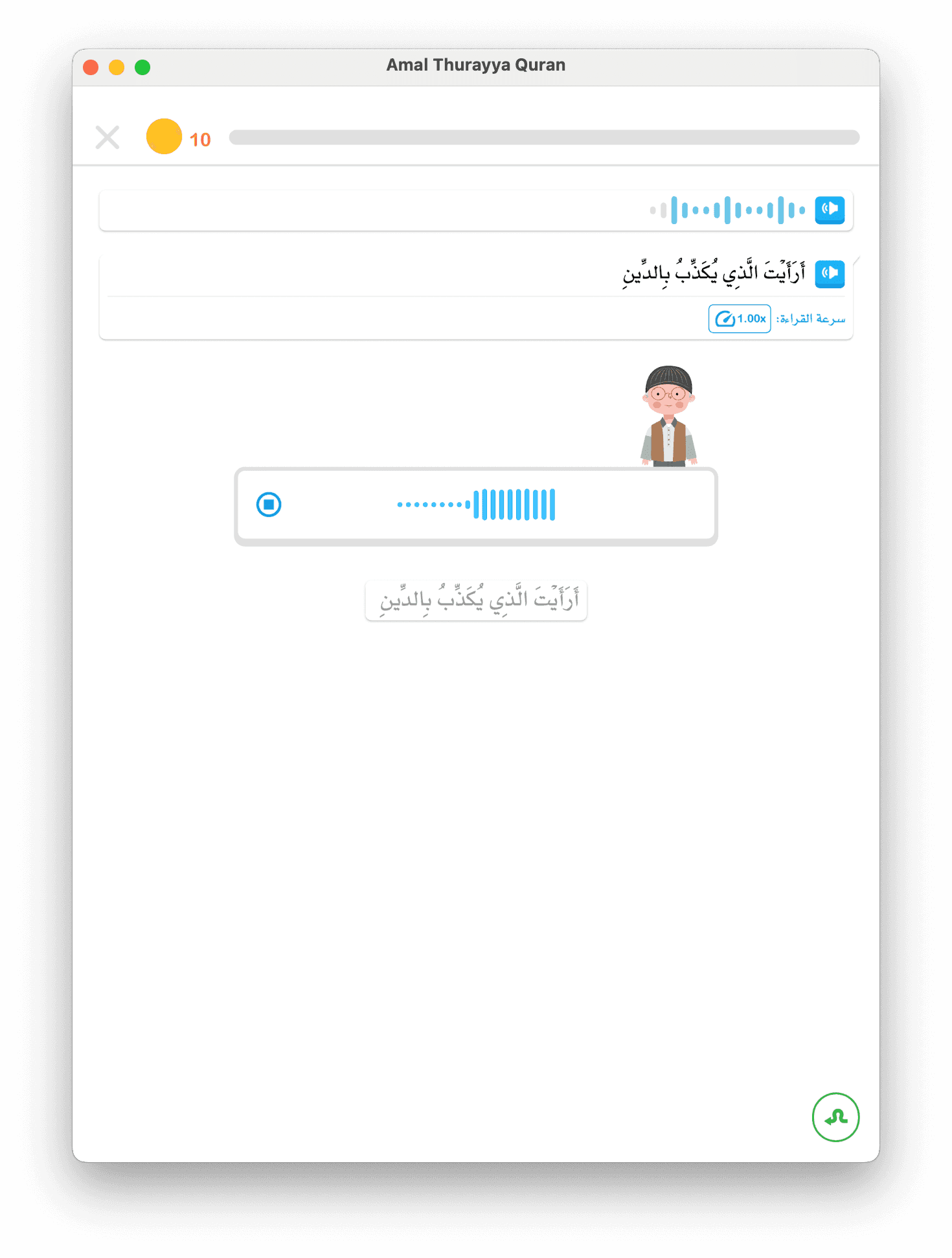
- Lapisan 1 — Device STT (Umpan Balik Instan)
DeviceSTTMechanismmenggunakan pengenalan suara asli Flutter untuk memproses audio secara lokal. Saat anak berbicara, hasil parsial mengalir kembali langsung — menampilkan sorotan hijau pada kata yang dikenali tanpa jeda. Ini menjaga keterlibatan anak dan memberikan penguatan seketika. Device STT bekerja offline dan tidak perlu koneksi internet. - Lapisan 2 — Backend Google STT (Akurasi)
Secara bersamaan, kami mengirim audio keBackendGoogleSTTMechanismyang menggunakan Google Cloud Speech-to-Text dengan bias konteks ucapan. Kami mengirim teks yang diharapkan (kata yang harus dibaca anak) sebagai petunjuk. Ini secara signifikan meningkatkan akurasi pengenalan kata Arab dalam konteks — STT "mengetahui" harus mendengar fonem spesifik.
| Lapisan | Latensi | Akurasi | Offline | Kasus Penggunaan |
|---|---|---|---|---|
| Device STT | ~100ms | 70% | ✓ | Tampilan WIP real-time |
| Cloud STT | ~500ms | 92% | ✗ | Penilaian akhir |
| Gabungan | 500ms | 95% | Partial | Pengalaman pengguna terbaik |
Penilaian Kesamaan, Bukan Pencocokan Biner
Kami tidak memeriksa apakah pengucapan anak "tepat benar" — tapi memberikan skor berdasarkan spektrum menggunakan kesamaan string dengan ambang 0.7. Ini memungkinkan:
- Variasi aksen: Anak dari berbagai wilayah penutur Arab mengucapkan dengan cara yang berbeda alami
- Artikulasi anak-anak: Anak kecil sering salah ucap yang membaik dengan latihan
- Kesadaran diakritik: "كَتَبَ" (dengan diakritik) vs "كتب" (tanpa) diperlakukan berbeda dalam konteks pengenalan kami
Anak mungkin mendapat skor 85% pada percobaan pertama, 91% pada kedua, dan 97% setelah latihan. Mereka melihat kemajuan progresif, bukan hasil lulus/gagal yang membuat putus asa.
Bias Konteks Ucapan: Rahasia Utama
Saat pelajaran meminta anak membaca "بِسْمِ اللَّهِ" (Dengan nama Allah), kami mengirim teks ini ke Google STT sebagai konteks ucapan. Mesin STT mengutamakan fonem spesifik tersebut, meningkatkan akurasi pengenalan sebesar 35-50% untuk kata yang diharapkan.
Ini penting untuk bahasa Arab karena:
- Kata memiliki banyak pengucapan sah tergantung diakritik
- Konteks membedakan makna
- Anak mendapat manfaat dari sistem yang "tahu" apa yang mereka baca
Mengapa Kompetitor Tidak Bisa Meniru
Memproduksi ini membutuhkan:
- Data pelatihan akustik suara anak (kami punya 95.000+ pelajar)
- Kesadaran diakritik Arab dalam pemrosesan suara (NLP khusus)
- Integrasi kurikulum (bias konteks terkait tiap pelajaran)
- Keahlian arsitektur mobile (STT ganda tanpa lag UI)
- Tahun iterasi dengan suara anak asli
Ini bukan fitur tambah — melainkan sistem yang dibangun dari dasar.
FAQ
T: Apakah Amal bekerja dengan berbagai aksen Arab?
J: Ya. Penilaian kesamaan kami mengakomodasi variasi dialek. Apakah anak Anda beraksen Teluk, Levant, atau Mesir, sistem menyesuaikan dan menilai pengucapan berdasarkan kejelasan, bukan standar tunggal.
T: Apakah anak saya butuh internet untuk pengenalan suara?
J: Device STT bekerja sepenuhnya offline untuk umpan balik instan. Untuk akurasi tertinggi (dan penjadwalan repetisi jarak jauh), cloud STT terbaik dengan internet, tapi aplikasi tetap berfungsi lancar dalam mode perangkat saja.
T: Apakah data suara anak saya disimpan?
J: Tidak. Audio diproses real-time dan langsung dihapus. Kami tidak pernah menyimpan rekaman suara anak. Hasil pengucapan dicatat (untuk analitik pembelajaran) tapi bukan audionya.