Device STT vs Cloud STT: Mengapa Kami Menggunakan Keduanya untuk Pengenalan Suara Anak
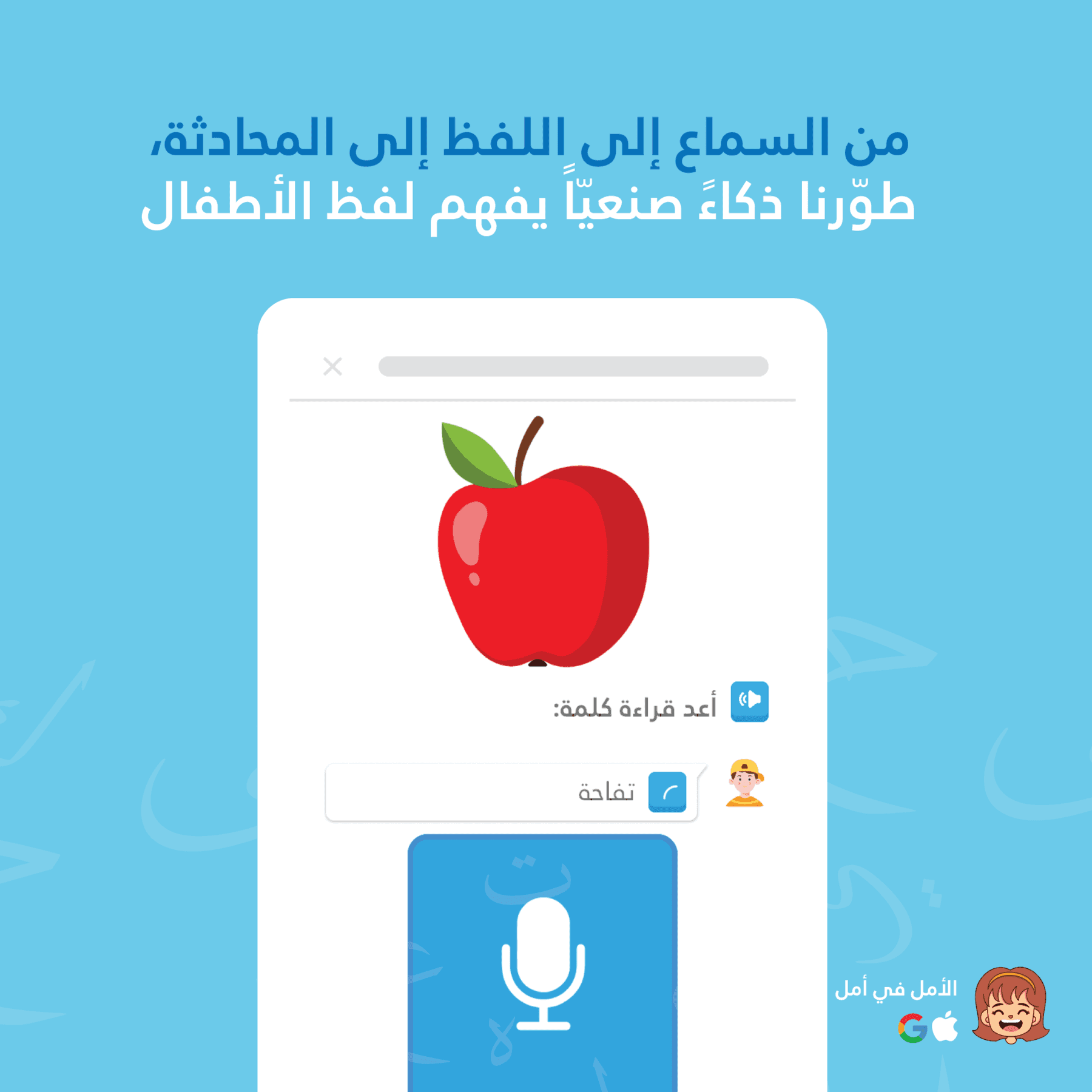
Amal dan Thurayya menggunakan arsitektur pengenalan suara ganda: Device STT untuk umpan balik instan tanpa jeda saat anak berbicara, dan Google Cloud Speech-to-Text untuk penilaian pengucapan yang lebih akurat setelah anak selesai berbicara. Pendekatan hibrida ini memberikan anak responsivitas langsung yang mereka butuhkan agar tetap tertarik sekaligus menjamin akurasi untuk pembelajaran bermakna.
Perbandingan Dasar
| Metode | Device STT | Cloud STT | Perlu Keduanya |
|---|---|---|---|
| Latensi | ~100ms | ~500ms | Umpan balik instan + akurasi |
| Akurasi | 70% | 92% | Penilaian kepercayaan |
| Offline | ✓ | ✗ | Ketahanan |
| Sadar Diakritik | Terbatas | Tinggi (dengan konteks) | Dukungan bahasa Arab lengkap |
| Detail Pengucapan | Kasaran | Timestamps per kata | Markah suara untuk animasi |
Anak membutuhkan keduanya secara bersamaan:
- Umpan balik instan menjaga keterlibatan (Device STT)
- Umpan balik akurat memastikan pembelajaran yang bermakna (Cloud STT)
Penjelasan Implementasi
Lapisan Device STT (DeviceSTTMechanism)
Menggunakan paket Flutter speech_to_text:
Anak mengucapkan "كتب" (kataba — menulis)
↓
[Device mengalirkan hasil parsial]
↓
UI menampilkan sorotan hijau: "كتب" (70% kepercayaan)
↓
[Latensi nol — anak melihat umpan balik saat berbicara]
Device STT sempurna untuk tampilan "pekerjaan dalam proses". Anak melihat apa yang didengar aplikasi secara real-time, menjaga keterlibatan dan memberikan konfirmasi audio langsung.
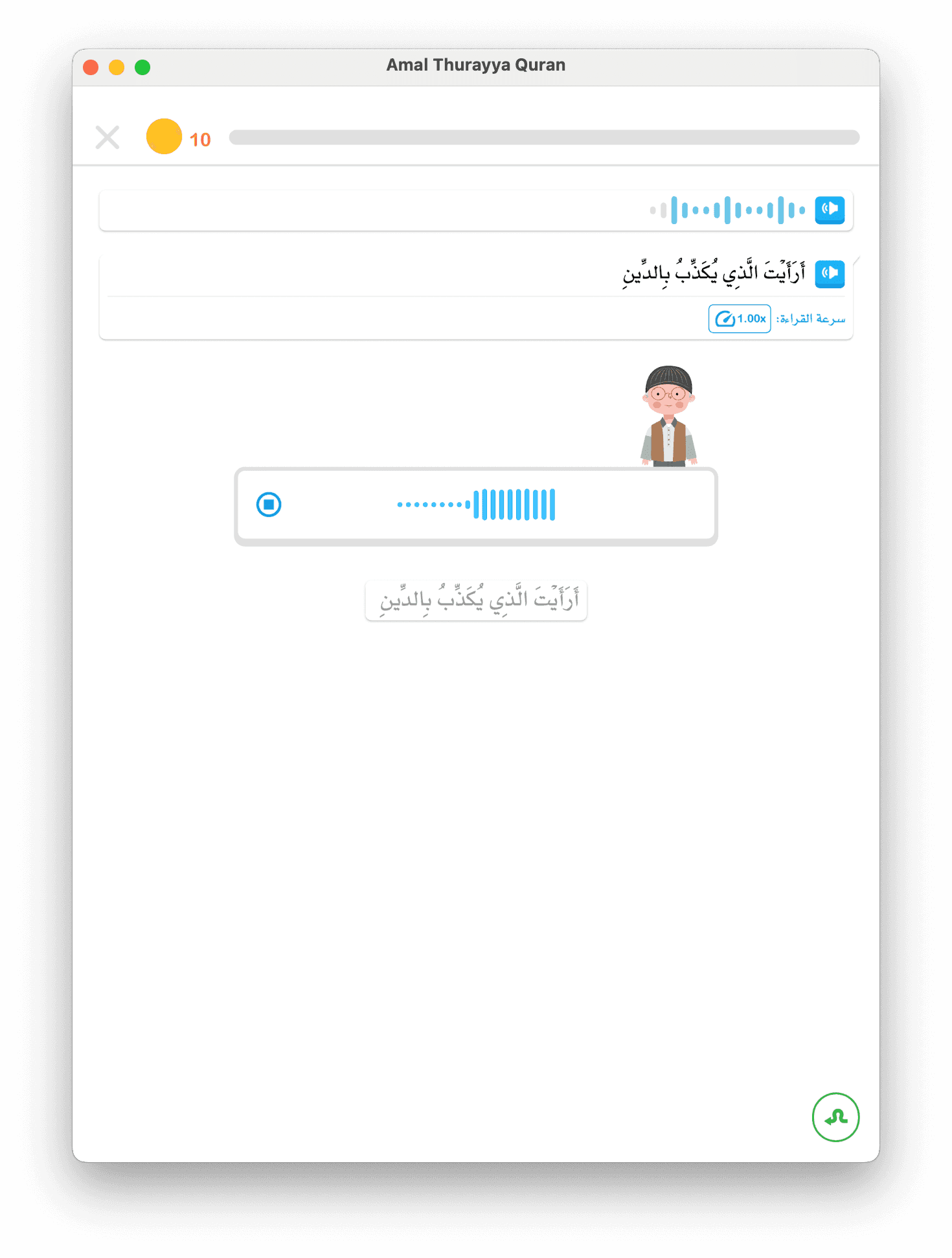
Lapisan Cloud STT (BackendGoogleSTTMechanism)
- Audio dikirim ke backend → Google Cloud Speech-to-Text
- Kami mengirim teks yang diharapkan sebagai petunjuk "speech context"
- Google mengembalikan tanda waktu per kata dan skor kepercayaan
- Backend melakukan perbandingan kemiripan (ambang 0,7)
- Hasil dikembalikan ke aplikasi untuk penilaian akhir
Cloud STT lebih lambat tapi jauh lebih akurat, terutama dengan konteks diakritik.
Bias Konteks Ucapan: Perubahan Besar
Google Speech-to-Text memungkinkan "adaptasi ucapan" — kami mengirim teks yang diharapkan sebagai petunjuk pengenalan. Ini sangat mengubah untuk bahasa Arab:
Tanpa bias konteks:
Anak membaca: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" (Basmala — doa pembuka)
Google menangkap: Kata Arab umum, akurasi 50-60%
Dengan bias konteks:
Anak membaca: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
Kami beritahu Google: "Cari frasa Quran ini secara tepat"
Google mengembalikan: Akurasi 92%+ dengan tanda waktu per kata
Benchmark internal: Bias konteks meningkatkan akurasi pengenalan 35-50% untuk teks yang diharapkan.
Tanda Waktu Per Kata untuk Markah Ucapan
Cloud STT mengembalikan:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
Tanda waktu ini menggerakkan:
- Animasi sinkronisasi bibir (blog #3): posisi mulut berubah tepat waktu
- Sorotan per kata: anak melihat kata yang sedang diucapkan
- Penentuan kesalahan: jika salah satu kata salah pengucapan, kami tahu kata mana
Penurunan Layanan yang Mulus
Jika cloud STT tidak tersedia (tidak ada internet, timeout API), sistem secara mulus hanya memakai Device STT. Anak tidak pernah melihat kesalahan — hanya umpan balik yang sedikit kurang akurat. Aplikasi tidak berhenti; hanya beralih ke mode perangkat saja.
Mengapa Pesaing Tidak Bisa Menyamai Ini
Replikasi ini membutuhkan:
- Keahlian arsitektur STT mobile (mengelola dua stream)
- Integrasi Google Cloud dengan adaptasi ucapan
- Infrastruktur backend untuk pemrosesan audio
- Penilaian kemiripan yang disesuaikan dengan diakritik Arab
- Polanya penurunan layanan yang mulus
- Data pembelajar 95.000+ untuk validasi akurasi
FAQ
T: Pengenalan suara mana yang digunakan untuk skor anak saya?
A: Cloud STT dengan bias konteks. Device STT hanya untuk umpan balik proses. Kami gabungkan keduanya untuk menentukan akurasi akhir.
T: Kenapa anak saya melihat teks hijau saat berbicara tapi hasil berbeda setelah selesai?
A: Device STT menampilkan hasil parsial yang kurang akurat secara real-time. Cloud STT yang lebih akurat datang setelah berbicara selesai. Kedua umpan balik itu penting.
T: Apakah penggunaan dua sistem STT lebih mahal?
A: Ya, tapi peningkatan akurasi dan keterlibatan sepadan dengan biaya. Kami optimasi dengan Device STT dulu lalu mengirim audio penuh ke cloud hanya untuk penilaian.