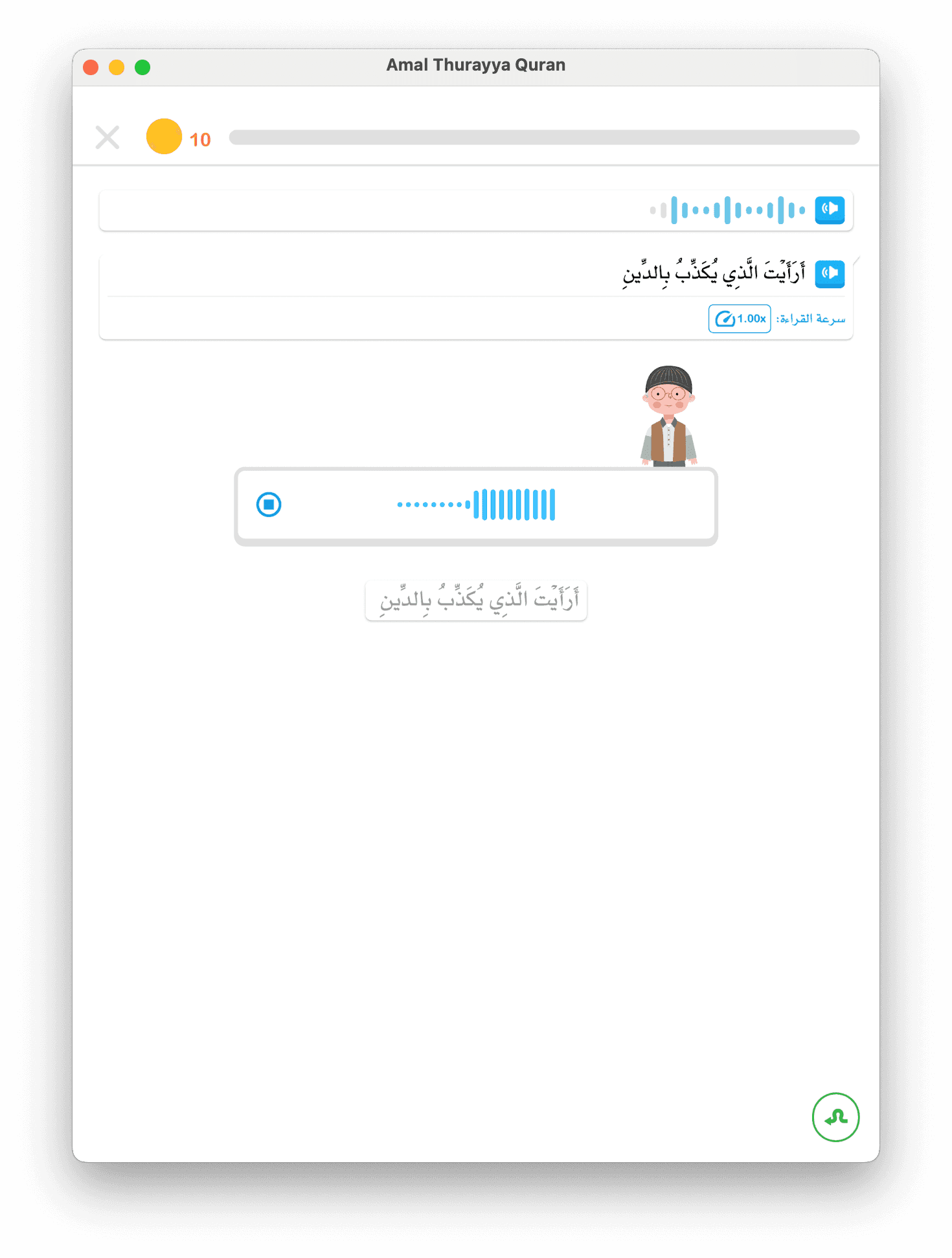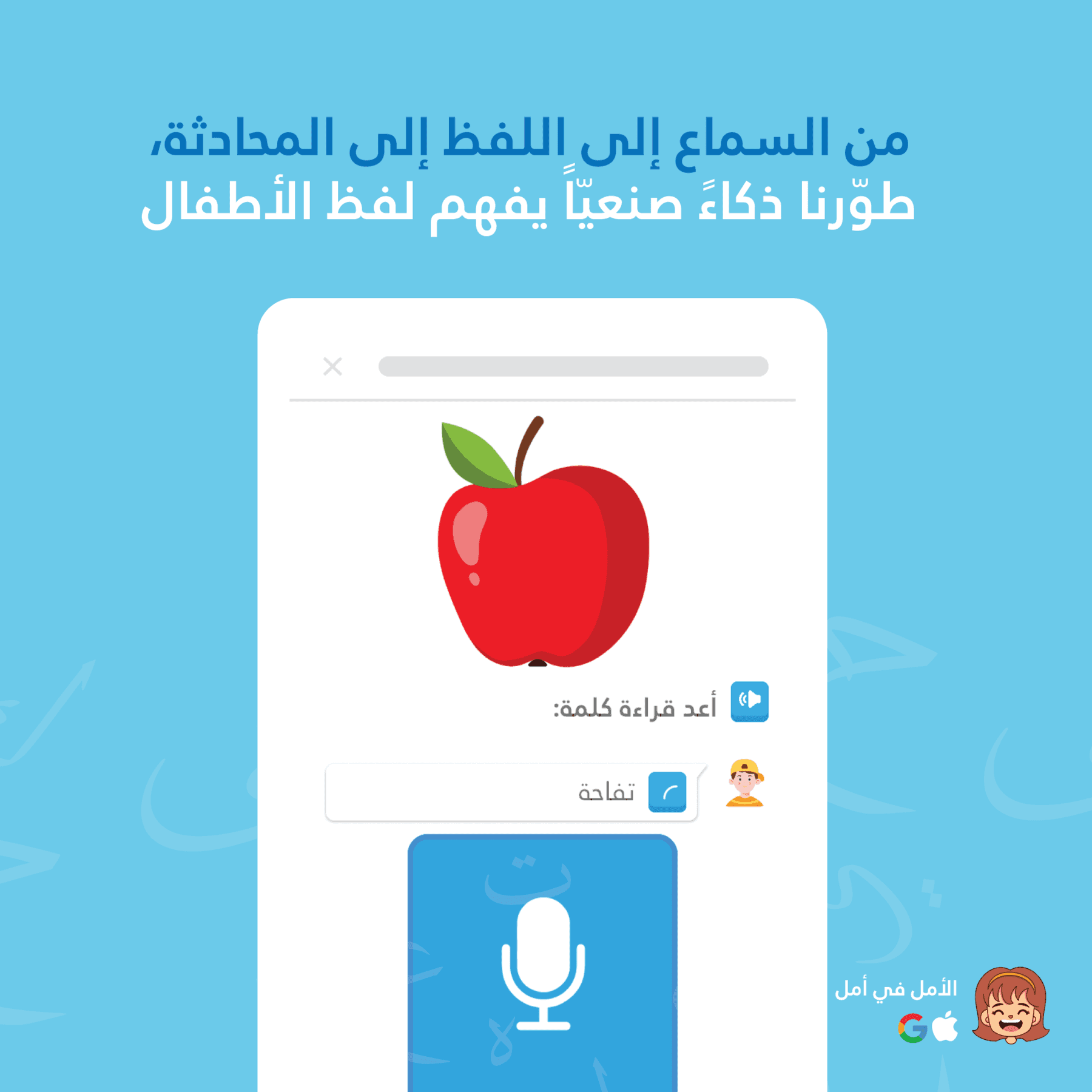
Amal utilise la reconnaissance vocale IA à deux couches, combinant le speech-to-text sur appareil pour des retours instantanés avec Google Cloud Speech-to-Text pour une précision accrue dans l'évaluation de la prononciation. Le système est spécifiquement ajusté aux voix des enfants lisant l'arabe, en tenant compte des marques diacritiques complètes (tashkeel). Aucune autre application d'apprentissage de l'arabe n'offre une correction de la prononciation en temps réel pour les enfants.
Le Problème que Nous Avons Résolu
L'arabe compte 28 lettres mais plus de 100 sons lorsqu'on inclut les diacritiques (fatha, damma, kasra, shadda, sukun, tanween). Les voix des enfants ont des propriétés acoustiques fondamentalement différentes de celles des adultes — un ton plus aigu, moins d'articulation, et un volume variable. Les modèles existants de speech-to-text, même les offres avancées de Google, n'étaient pas entraînés sur des enfants lisant l'arabe avec des marques diacritiques complètes.
La plupart des applications ignorent simplement le retour sur la prononciation ou utilisent un simple appariement de forme d'onde qui pénalise les accents et la variation naturelle. Ni l'une ni l'autre approche ne fonctionne pour les enfants apprenant une langue avec des sons qui n'existent pas en anglais.
Comment ça Marche : Architecture STT Double
Notre système exécute deux chemins de reconnaissance vocale simultanés :
Couche 1 — Device STT (Retour Instantané)
Le DeviceSTTMechanism utilise la reconnaissance vocale native de Flutter pour traiter l'audio localement. Lorsque votre enfant parle, les résultats partiels reviennent instantanément — montrant des mots reconnus en vert sans latence. Cela garde les enfants engagés et fournit un renforcement immédiat. Device STT fonctionne hors ligne et ne nécessite pas de connexion internet.
Couche 2 — Backend Google STT (Précision)
Simultanément, nous envoyons l'audio à BackendGoogleSTTMechanism, qui utilise Google Cloud Speech-to-Text avec un biais de contexte de la parole. Nous envoyons le texte attendu (le mot que l'enfant est censé lire) comme indice. Cela améliore considérablement la précision de reconnaissance pour les mots arabes en contexte — le STT "sait" écouter des phonèmes spécifiques.
| Couche | Latence | Précision | Hors ligne | Cas d'utilisation |
|---|---|---|---|---|
| Device STT | ~100ms | 70% | ✓ | Affichage WIP en temps réel |
| Cloud STT | ~500ms | 92% | ✗ | Évaluation finale |
| Combiné | 500ms | 95% | Partiel | Meilleure expérience utilisateur |
Évaluation de Similarité, Pas d'Appariement Binaire
Nous ne vérifions pas si la prononciation de votre enfant est "exactement correcte" — nous la notons sur un spectre en utilisant la similarité de chaîne avec un seuil de 0,7. Cela permet de :
- Variation d'accent : Les enfants de différentes régions arabophones prononcent naturellement différemment
- Articulation enfantine : Les jeunes enfants prononcent mal des sons qui s'améliorent avec la pratique
- Sensibilité aux diacritiques : "كَتَبَ" (avec diacritiques) vs "كتب" (sans) sont traités différemment dans notre contexte de reconnaissance
Un enfant peut avoir un score de 85% à sa première tentative, 91% à la seconde, et 97% après pratique. Ils voient une amélioration progressive, pas un pass/fail binaire décourageant.
Biais de Contexte de la Parole : L'Ingrédient Secret
Quand une leçon demande à votre enfant de lire "بِسْمِ اللَّهِ" (Au nom d'Allah), nous envoyons ce texte à Google STT comme contexte de parole. Le moteur STT penche vers ces phonèmes spécifiques, améliorant de 35-50% l'exactitude de reconnaissance des mots attendus.
C'est crucial pour l'arabe parce que :
- Les mots ont plusieurs prononciations valables selon la diacritisation
- Le contexte désambiguïse le sens
- Les enfants bénéficient du système "sachant" ce qu'ils sont censés lire
Pourquoi les Concurrents ne Peuvent Pas Copier Cela
Cela exige :
- Données d'entraînement acoustique de voix d'enfants (nous avons 95 000+ apprenants)
- Sensibilité aux diacritiques arabes dans le traitement de la parole (NLP spécialisé)
- Intégration au programme (biais de contexte lié à chaque leçon)
- Expertise en architecture mobile (double STT sans décalage UI)
- Des années d'itérations avec de vraies voix d'enfants
Ce n'est pas une fonctionnalité à ajouter — c'est un système à construire de zéro.
FAQ
Q : Amal fonctionne-t-il avec différents accents arabes ? R : Oui. Notre évaluation de similarité s'adapte à la variation dialectale. Que votre enfant ait un accent du Golfe, levantin ou égyptien, le système ajuste et évalue la prononciation sur l'intelligibilité, pas la conformité à une norme unique.
Q : Mon enfant a-t-il besoin d'internet pour la reconnaissance vocale ? R : Device STT fonctionne complètement hors ligne pour un retour instantané. Pour la plus grande précision (et la planification de la répétition espacée), Cloud STT fonctionne mieux avec internet, mais l'application se replie gracieusement en mode appareil uniquement.
Q : Les données vocales de mon enfant sont-elles stockées ? R : Non. L'audio est traité en temps réel et immédiatement supprimé. Nous ne stockons jamais les enregistrements vocaux des enfants. Les résultats de la parole sont consignés (pour l'analyse de l'apprentissage) mais pas l'audio lui-même.