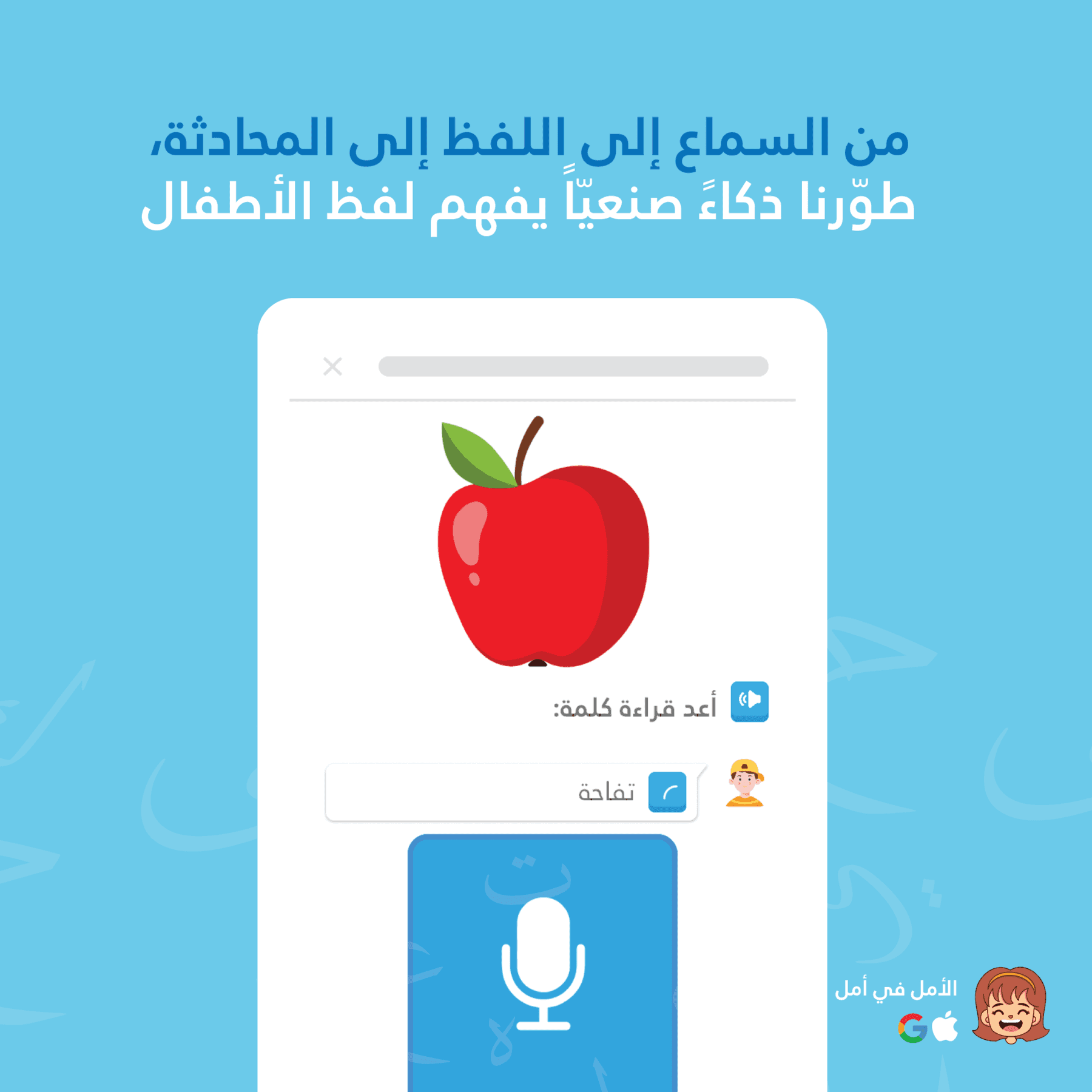
Amal et Thurayya utilisent une architecture double de reconnaissance vocale : le STT sur appareil pour un retour instantané sans latence pendant que l'enfant parle, et Google Cloud Speech-to-Text pour une évaluation précise de la prononciation après que l'enfant ait terminé. Cette approche hybride offre aux enfants une réactivité immédiate pour rester engagés tout en assurant la précision pour un apprentissage significatif.
Le compromis fondamental
| Métrique | STT sur appareil | STT Cloud | Besoin des deux |
|---|---|---|---|
| Latence | ~100ms | ~500ms | Feedback instantané + précision |
| Précision | 70% | 92% | Scoring de confiance |
| Hors ligne | ✓ | ✗ | Résilience |
| Sensibilité aux diacritiques | Limité | Élevée (avec contexte) | Support complet arabe |
| Détail de prononciation | Grossier | Horodatages au niveau des mots | Marques de discours pour animation |
L'enfant a besoin des deux simultanément:
- Le retour instantané maintient l'engagement (STT sur appareil)
- Le retour précis assure un véritable apprentissage (STT Cloud)
Approfondissement de l'implémentation
Couche STT sur appareil (DeviceSTTMechanism)
Utilise le package Flutter speech_to_text:
L'enfant dit "كتب" (kataba - a écrit)
↓
[Appareil transmet des résultats partiels]
↓
L'interface montre des surlignements verts : "كتب" (70% de confiance)
↓
[Zéro latence - l'enfant voit le retour pendant qu'il parle]
Le STT sur appareil est parfait pour l'affichage "en cours". Les enfants voient ce que l'application entend en temps réel, ce qui maintient l'engagement et fournit une confirmation audio immédiate.
Couche STT Cloud (BackendGoogleSTTMechanism)
- L'audio est envoyé au backend → Google Cloud Speech-to-Text
- Nous envoyons le texte attendu comme une suggestion de « contexte de parole »
- Google renvoie des horodatages au niveau des mots et des scores de confiance
- Le backend effectue une comparaison de similarité (seuil de 0,7)
- Le résultat est renvoyé à l'application pour l'évaluation finale
Le STT Cloud est plus lent mais beaucoup plus précis, surtout avec le contexte diacritique.
Biais de contexte de parole : Un changeur de jeu
Google Speech-to-Text permet « l'adaptation de la parole » — nous envoyons le texte attendu comme un indice de reconnaissance. Cela est transformateur pour l'arabe :
Sans biais de contexte : L'enfant récite : "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" (Basmala - phrase d'ouverture de prière) Google entend : Mots arabes génériques, 50-60% de précision
Avec biais de contexte : L'enfant récite : "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" Nous disons à Google : « Écoutez cette phrase coranique exacte » Google renvoie : 92%+ de précision avec horodatages au niveau des mots
Benchmarks internes : Le biais de contexte améliore la précision de reconnaissance de 35 à 50% pour le texte attendu.
Horodatages au niveau des mots pour les marques de discours
Le STT Cloud retourne :
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
Ces horodatages pilotent :
- Animations labiales (blog #3) : changement de position de la bouche à des moments précis
- Mise en évidence par mot : l'enfant voit sur quel mot exact il est
- Repérage d'erreur : s'il prononce mal un mot dans une phrase, nous savons lequel
Dégradation progressive
Si le STT Cloud est indisponible (pas d'Internet, délai API), le système utilise gracieusement le STT sur appareil seul. Les enfants ne voient jamais d'erreur – ils reçoivent simplement un retour légèrement moins précis. L'application ne se dérange pas; elle se réduit simplement au mode appareil seulement.
Pourquoi les concurrents ne peuvent pas égaler cela
Reproduire cela nécessite :
- Expertise en architecture mobile STT (gestion des flux doubles)
- Intégration Google Cloud avec adaptation de la parole
- Infrastructure backend pour le traitement audio
- Scoring de similarité adapté aux diacritiques arabes
- Modèles de dégradation progressive
- Données de plus de 95 000 apprenants pour valider la précision
FAQ
Q : Quelle reconnaissance vocale est utilisée pour le score de mon enfant ? R : STT Cloud avec biais de contexte. Le STT sur appareil est pour le retour en cours. Nous combinons les deux pour déterminer la précision finale.
Q : Pourquoi mon enfant voit-il du texte vert en parlant mais des résultats différents après ? R : Le STT sur appareil montre des résultats partiels, moins précis en temps réel. Les résultats plus précis du STT Cloud arrivent après que l'enfant ait fini de parler. Les deux boucles de retour sont précieuses.
Q : L'utilisation de deux systèmes STT coûte-t-elle plus cher ? R : Oui, mais l'amélioration de la précision et de l'engagement justifie le coût. Nous optimisons en utilisant d'abord le STT sur appareil et n'envoyons l'audio complet au cloud que pour le scoring.