Reconhecimento de Fala no Dispositivo vs na Nuvem: Por Que Usamos Ambos para Crianças
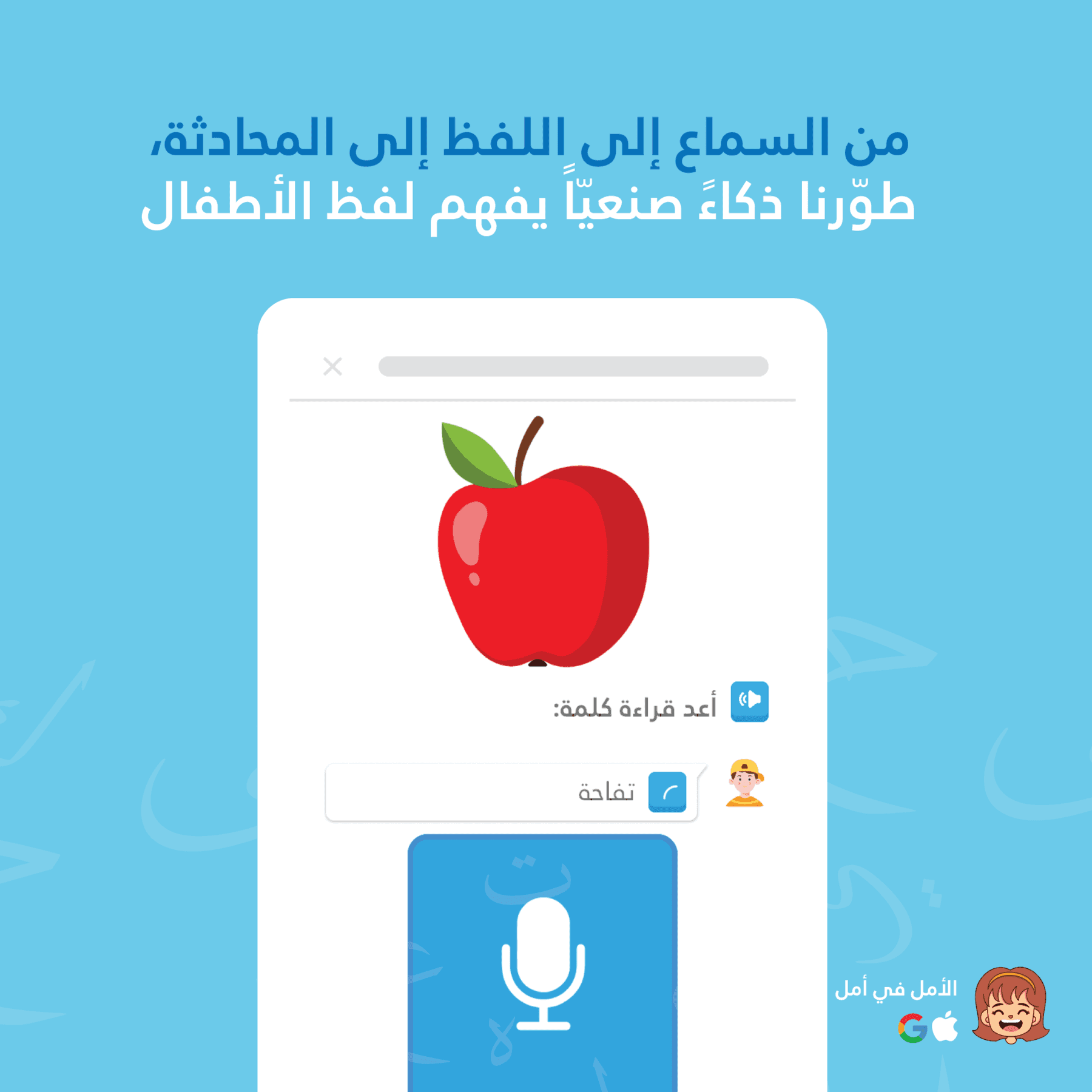
Amal e Thurayya utilizam uma arquitetura dupla de reconhecimento de fala: STT no dispositivo para feedback instantâneo e sem latência enquanto a criança fala, e o Google Cloud Speech-to-Text para uma avaliação de pronúncia mais precisa após a criança terminar. Essa abordagem híbrida oferece aos crianças a resposta imediata que precisam para se manterem engajadas, garantindo precisão para um aprendizado significativo.
A Troca Fundamental
| Métrica | STT no Dispositivo | Cloud STT | Por Que Usar Ambos |
|---|---|---|---|
| Latência | ~100ms | ~500ms | Feedback instantâneo + precisão |
| Precisão | 70% | 92% | Avaliação confiável |
| Offline | ✓ | ✗ | Resiliência |
| Consciência de diacríticos | Limitada | Alta (com contexto) | Suporte completo ao árabe |
| Detalhe de pronúncia | Grossa | Marcação por palavra | Marcas de fala para animação |
A criança precisa dos dois simultaneamente:
- Feedback imediato mantém o engajamento (STT no dispositivo)
- Feedback preciso garante aprendizado real (Cloud STT)
Detalhes da Implementação
Camada STT no Dispositivo (DeviceSTTMechanism)
Usa o pacote Flutter speech_to_text:
Criança fala "كتب" (kataba — escreveu)
↓
[Dispositivo transmite resultados parciais]
↓
UI exibe destaques verdes: "كتب" (70% de confiança)
↓
[Latência zero — feedback aparece enquanto fala]
O STT no dispositivo é perfeito para mostrar o progresso em tempo real. As crianças veem o que o app está ouvindo, o que mantém o engajamento e confirma o áudio imediatamente.
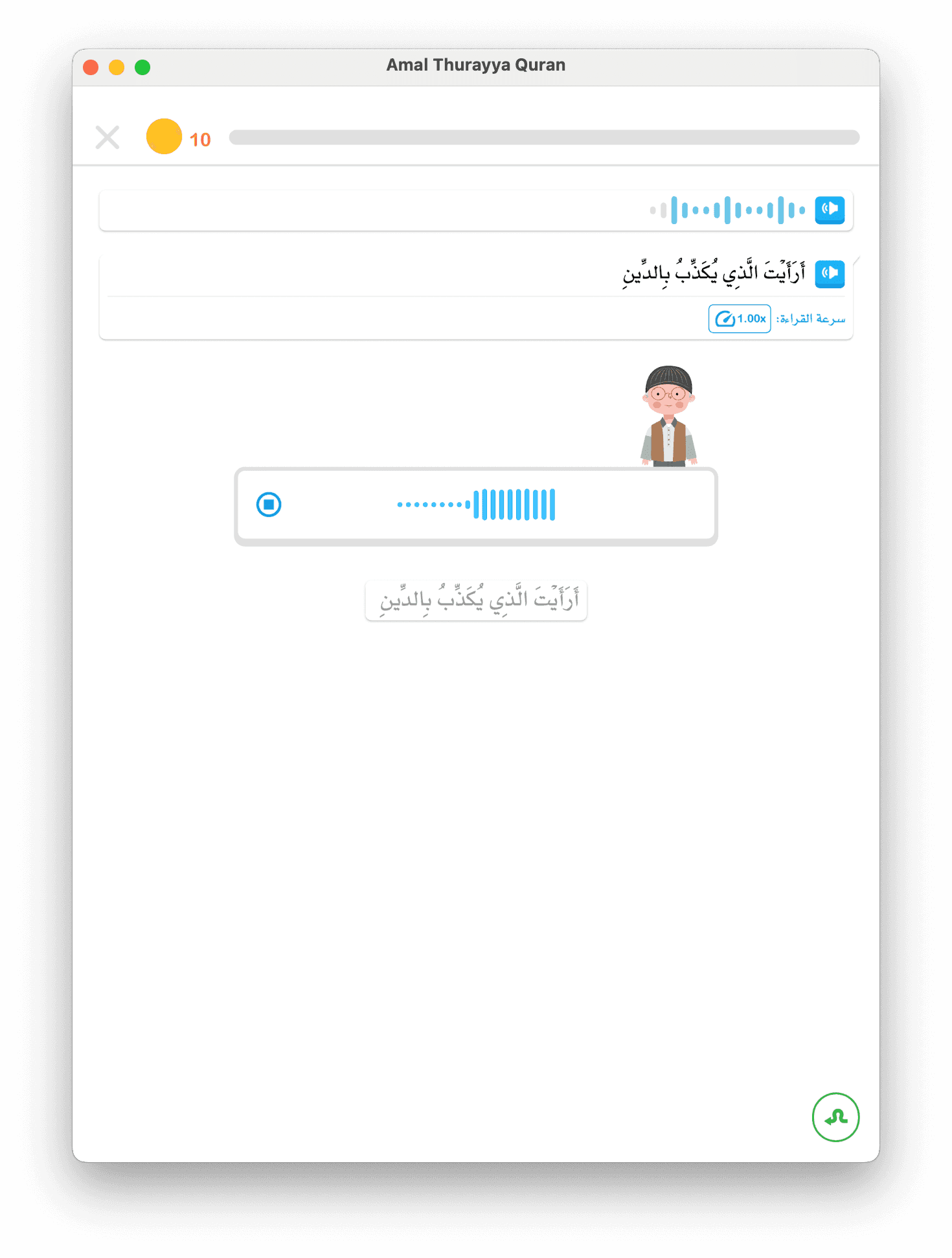
Camada Cloud STT (BackendGoogleSTTMechanism)
1. O áudio é enviado ao backend → Google Cloud Speech-to-Text
2. Enviamos o texto esperado como dica de "contexto de fala"
3. O Google retorna carimbos de tempo palavra a palavra e pontuações de confiança
4. O backend compara similaridade (limiar 0,7)
5. O resultado é enviado ao app para pontuação final
O Cloud STT é mais lento, mas muito mais preciso, especialmente com o contexto diacrítico.
Biasing de Contexto de Fala: Uma Revolução
O Google Speech-to-Text permite "adaptação de fala" — enviamos o texto esperado como dica para reconhecimento. Isso é fundamental para o árabe:
Sem biasing de contexto:
Criança recita: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" (Basmala — frase inicial do Alcorão)
Google entende: palavras árabes genéricas, 50-60% de precisão
Com biasing de contexto:
Criança recita: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
Nós informamos ao Google: "Procure essa frase exata do Alcorão"
Google retorna: precisão superior a 92% com carimbos de tempo palavra a palavra
Benchmarks internos: Biasing aumenta a acurácia em 35-50% para textos esperados.
Carimbos de Tempo Palavra a Palavra para Marcas de Fala
O Cloud STT retorna:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
Esses carimbos alimentam:
1. Animações de sincronização labial (blog #3): posição da boca muda nos momentos exatos
2. Destaque palavra a palavra: criança vê em qual palavra está
3. Identificação de erros: se errar uma palavra na frase, sabemos qual
Degradação Elegante
Se o Cloud STT não estiver disponível (sem internet, timeout da API), o sistema usa apenas o STT do dispositivo. A criança nunca vê erro, apenas feedback um pouco menos preciso. O app não trava; ele só volta para modo dispositivo apenas.
Por Que Concorrentes Não Conseguem Isso
Reproduzir isso exige:
1. Especialização em arquitetura móvel STT (gerenciamento de fluxos duplos)
2. Integração Google Cloud com adaptação de fala
3. Infraestrutura backend para processamento de áudio
4. Pontuação de similaridade afinada para diacríticos árabes
5. Padrões de degradação elegante
6. Dados de mais de 95.000 aprendizes para validar precisão
Perguntas Frequentes
P: Qual reconhecimento de fala é usado para a pontuação do meu filho?
R: O Cloud STT com biasing de contexto. O STT do dispositivo serve só para feedback em andamento. Combinamos ambos para a pontuação final.
P: Por que meu filho vê texto verde enquanto fala, mas resultados diferentes depois?
R: O STT do dispositivo mostra resultados parciais e menos precisos em tempo real. O Cloud STT traz resultados mais precisos após a fala. Ambos os retornos são úteis.
P: Usar dois sistemas STT custa mais?
R: Sim, mas a melhoria na precisão e engajamento justifica. Otimizamos usando primeiro o STT do dispositivo e enviamos áudio completo ao cloud só para a avaliação final.