Geräte-STT vs Cloud-STT: Warum wir beides für die Spracherkennung bei Kindern nutzen
Amal und Thurayya verwenden eine doppelte Spracherkennungsarchitektur: Geräte-STT für sofortiges, verzögerungsfreies Feedback, während das Kind spricht, und Google Cloud Speech-to-Text für eine genauere Aussprachebewertung, nachdem das Kind fertig gesprochen hat. Dieser hybride Ansatz bietet Kindern die sofortige Reaktionsfähigkeit, die sie benötigen, um engagiert zu bleiben, und gewährleistet gleichzeitig Genauigkeit für ein sinnvolles Lernen.
Der grundlegende Kompromiss
| Metrik | Geräte-STT | Cloud-STT | Beides notwendig |
|---|---|---|---|
| Latenz | ~100ms | ~500ms | Sofortiges Feedback + Genauigkeit |
| Genauigkeit | 70% | 92% | Verlässliche Bewertung |
| Offline | ✓ | ✗ | Ausfallsicherheit |
| Diatritenbewusstsein | Begrenzt | Hoch (mit Kontext) | Volle Arabisch-Unterstützung |
| Aussprachedetail | Grob | Wortgenaue Zeitstempel | Sprechmarken für Animation |
Das Kind braucht beides gleichzeitig:
- Sofortiges Feedback hält das Engagement aufrecht (Geräte-STT)
- Genaues Feedback sichert reales Lernen (Cloud-STT)
Implementierung im Detail
Geräte-STT-Schicht (DeviceSTTMechanism)
Verwendet das speech_to_text Flutter-Paket:
Kind spricht "كتب" (kataba — schrieb)
↓
[Gerät streamt Teilresultate]
↓
UI zeigt grüne Markierungen: "كتب" (70% Vertrauen)
↓
[Null Latenz – Kind sieht Feedback beim Sprechen]
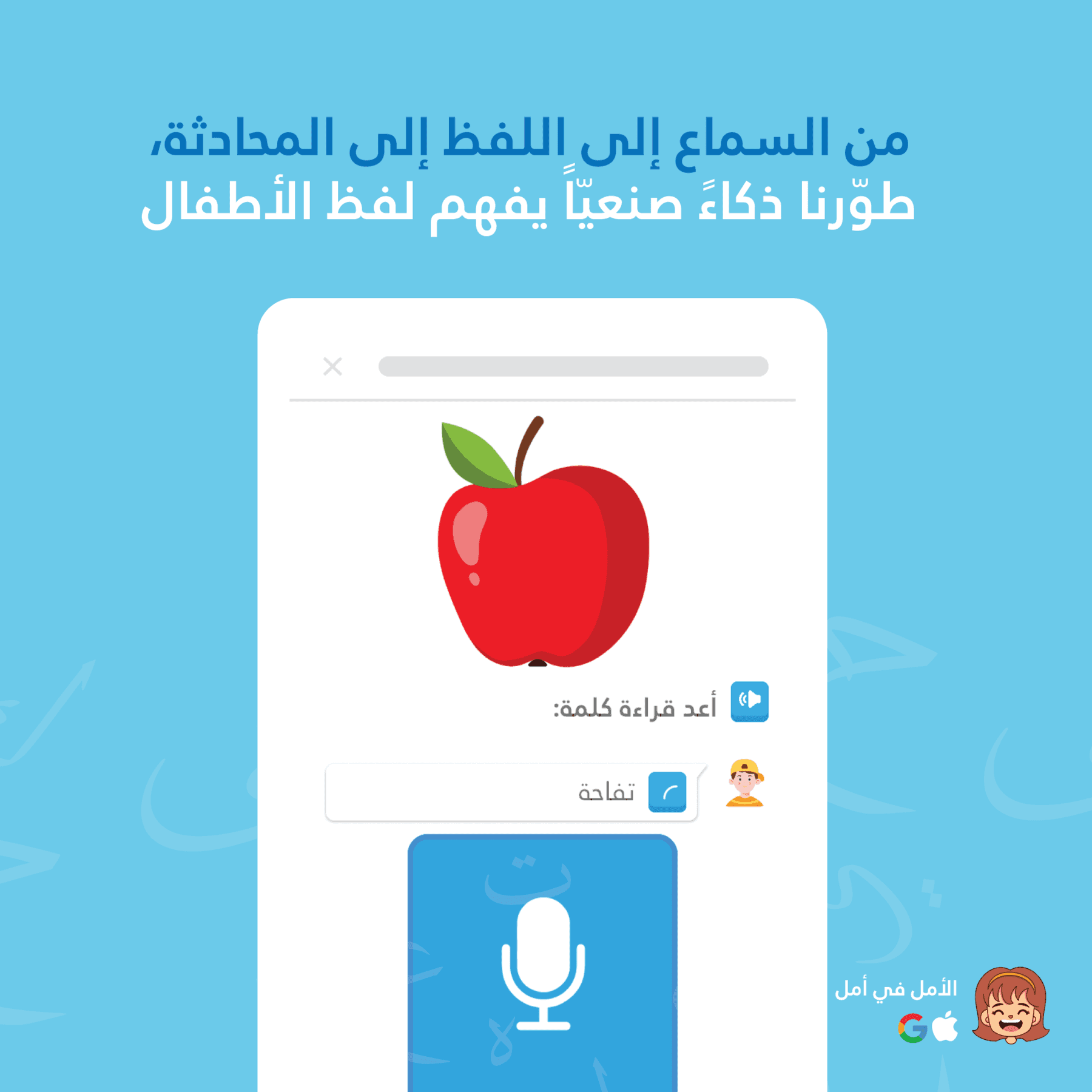
Die Geräte-STT ist perfekt für die Anzeige "in Arbeit" geeignet. Kinder sehen, was die App in Echtzeit hört, was das Engagement aufrechterhält und sofortige audio-visuelle Bestätigung bietet.
Cloud-STT-Schicht (BackendGoogleSTTMechanism)
- Audio wird an Backend gesendet → Google Cloud Speech-to-Text
- Wir senden den erwarteten Text als "Sprachkontext"-Hinweis
- Google liefert wortgenaue Zeitstempel und Vertraulichkeitswerte
- Backend führt Ähnlichkeitsvergleich durch (0.7 Schwelle)
- Ergebnis wird zur endgültigen Bewertung an die App zurückgegeben
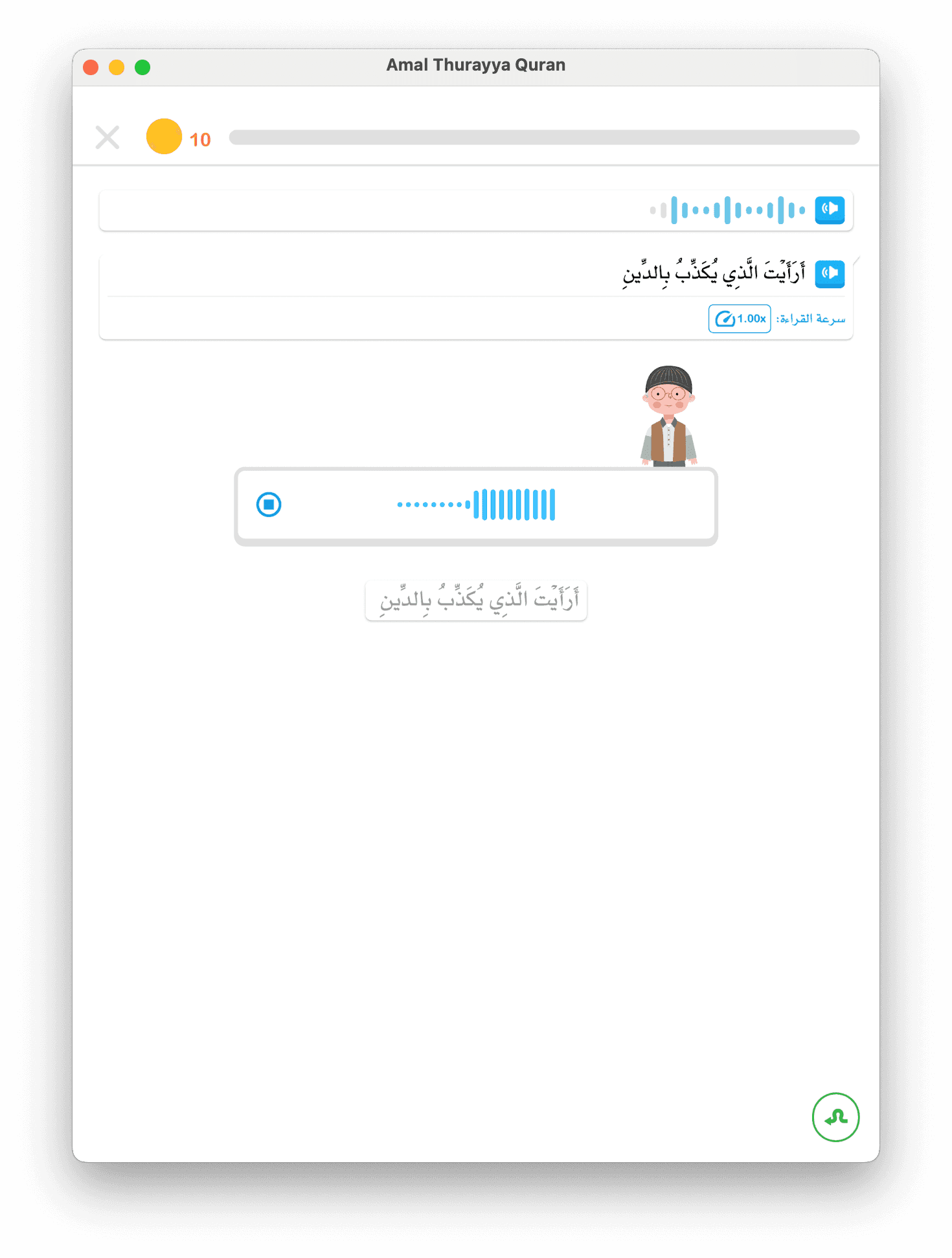
Cloud STT ist langsamer, aber weitaus genauer, insbesondere im Kontext diakritischer Zeichen.
Sprachkontext-Biasing: Der Game-Changer
Google Speech-to-Text ermöglicht "Sprachanpassung" – wir senden den erwarteten Text als Anerkennungshinweis. Dies ist revolutionär für Arabisch:
Ohne Kontextbiasing:
Kind rezitiert: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" (Basmala – die Eröffnungsgebetsphrase)
Google hört: Allgemeine arabische Wörter, 50-60% Genauigkeit
Mit Kontextbiasing:
Kind rezitiert: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
Wir sagen Google: "Hör auf diese exakte koranische Phrase"
Google liefert: 92%+ Genauigkeit mit wortgenauen Zeitstempeln
Interne Benchmarks: Kontextbiasing verbessert die Erkennungsgenauigkeit um 35-50% für erwarteten Text.
Wortgenaue Zeitstempel für Sprechmarken
Cloud STT liefert:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
Diese Zeitstempel unterstützen:
- Lippensynchronisation-Animationen (blog #3): Mundposition ändert sich zu genauen Zeiten
- Wortweise Hervorhebung: Kind sieht, bei welchem Wort es ist
- Fehlerortung: Bei Fehlbetonung wissen wir, welches Wort betroffen ist
Gleitende Degradierung
Wenn Cloud-STT nicht verfügbar ist (kein Internet, API-Zeitüberschreitung), nutzt das System sanft allein Geräte-STT. Kinder sehen nie einen Fehler – sie erhalten nur etwas weniger genaues Feedback. Die App bricht nicht zusammen; sie wird lediglich auf Geräte-Only-Modus zurückgesetzt.
Warum Mitbewerber das nicht kopieren können
Eine Nachbildung erfordert:
- Expertise in mobiler STT-Architektur (Verwalten von Dual-Streams)
- Integration von Google Cloud mit Sprachadaption
- Backend-Infrastruktur für Audioverarbeitung
- Ähnlichkeitsbewertung abgestimmt auf arabische Diakritika
- Muster für gleitende Degradierung
- 95.000+ Lerndaten zum Validieren der Genauigkeit
FAQ
F: Welche Spracherkennung wird für die Bewertung meines Kindes verwendet?
A: Cloud-STT mit Kontextbiasing. Geräte-STT ist nur für WIP-Feedback. Wir kombinieren beide, um die endgültige Genauigkeit zu bestimmen.
F: Warum sieht mein Kind grünen Text beim Sprechen, aber andere Ergebnisse danach?
A: Geräte-STT zeigt partielle, weniger genaue Ergebnisse in Echtzeit. Die genaueren Ergebnisse von Cloud-STT kommen nach dem Ende des Sprechens an. Beide Feedback-Schleifen sind wertvoll.
F: Verursachen zwei STT-Systeme höhere Kosten?
A: Ja, aber die Verbesserungen in Genauigkeit und Engagement rechtfertigen die Kosten. Wir optimieren, indem wir zuerst Geräte-STT nutzen und nur vollständiges Audio zur Bewertung an die Cloud senden.