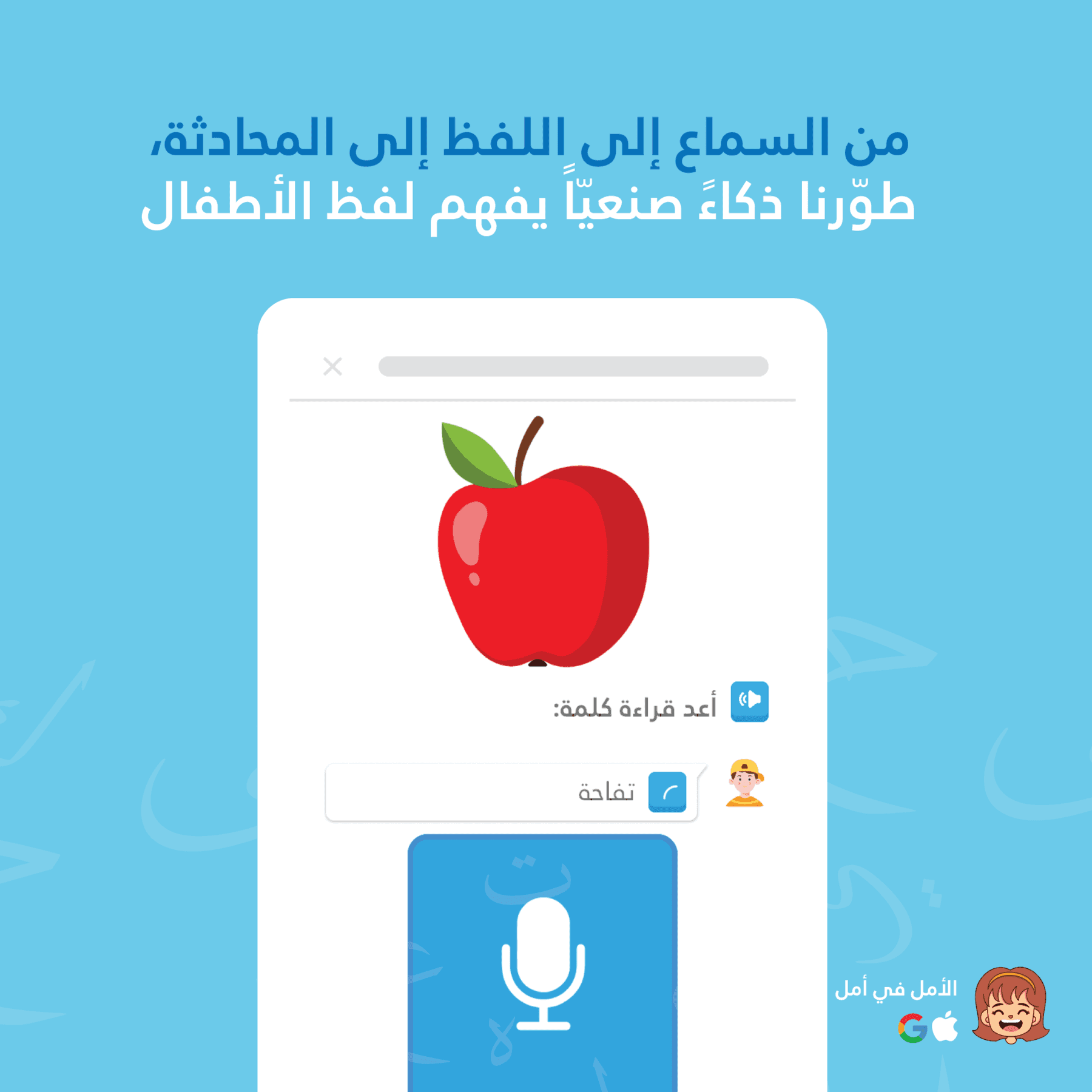
STT الجهاز مقابل STT السحابي للأطفال: لماذا نستخدمهما معاً
تستخدم Amal وThurayya بنية تعرّف صوتي مزدوجة: STT على الجهاز لتقديم ملاحظات فورية وبدون تأخير أثناء حديث الطفل، وGoogle Cloud Speech-to-Text لتقييم النطق بدقة أعلى بعد انتهاء الطفل من الحديث. هذه الطريقة الهجينة تمنح الأطفال الاستجابة الفورية للحفاظ على التفاعل، مع ضمان الدقة من أجل تعلم مثمر.
المفاضلة الأساسية
| المعيار | STT الجهاز | STT السحابي | الحاجة لكلاهما |
|---|---|---|---|
| التأخير | ~100مللي ثانية | ~500مللي ثانية | تغذية راجعة فورية + الدقة |
| الدقة | 70% | 92% | تقدير الثقة |
| غير متصل | ✓ | ✗ | المرونة |
| وعي بالشكل | محدود | عالي (مع السياق) | دعم كامل للعربية |
| تفاصيل النطق | غير تفصيلية | علامات زمنية لكلمات | علامات نطق للرسوم المتحركة |
الطفل يحتاج لكلاهما في آنٍ واحد:
- الملاحظات الفورية تُبقيهم متفاعلين (STT الجهاز)
- التغذية الراجعة الدقيقة تضمن تعلماً حقيقياً (STT السحابي)
التنفيذ بتعمق
طبقة STT الجهاز (DeviceSTTMechanism)
يستخدم حزمة Flutter speech_to_text:
الطفل يقول "كتب" (كتب — كتب)
↓
[الجهاز يبث النتائج الجزئية]
↓
واجهة المستخدم تظهر تمييزات خضراء: "كتب" (70% ثقة)
↓
[بدون تأخير — يرى الطفل الملاحظات أثناء التحدث]
STT الجهاز مناسب تماماً لعرض "ما يتم العمل عليه". يرى الأطفال ما تسمعه التطبيق في الوقت الفعلي، مما يحافظ على التفاعل ويقدم تأكيدًا صوتيًا فوريًا.
طبقة STT السحابي (BackendGoogleSTTMechanism)
- الصوت يُرسل إلى الخلفية → Google Cloud Speech-to-Text
- نرسل النص المتوقع كإشارة "سياق الكلام"
- تعيد Google علامات زمنية لكل كلمة ودرجات الثقة
- الخلفية تقوم بمقارنة التشابه (عتبة 0.7)
- يُعاد النتيجة إلى التطبيق للتقييم النهائي
STT السحابي أبطأ ولكنه أكثر دقة بكثير، خاصة مع سياق الشكلات.
توجيه سياق الكلام: المحول للأسواق
تسمح Google Speech-to-Text بتكييف الكلام — نرسل النص المتوقع كإشارة للتعرف. هذا محوري للعربية:
بدون توجيه السياق:
الطفل يتلو: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
Google تسمع: كلمات عربية عامة، 50-60% دقة
مع توجيه السياق:
الطفل يتلو: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
نقول لـGoogle: "استمع لهذه العبارة القرآنية بالتحديد"
تعيد Google: 92%+ دقة مع علامات زمنية لكل كلمة
المعايير الداخلية: تحسن توجيه السياق دقة التعرف بنسبة 35-50% للنص المتوقع.
علامات زمنية على مستوى الكلمة لعلامات النطق
تعيد STT السحابي:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
تدعم هذه العلامات الزمنية:
- رسوم الشفاة المتزامنة (بلوق #3): تغييرات موضع الفم في لحظات محددة
- تمييز الكلمة بالكلمة: يرى الطفل أي كلمة يتحدثون عنها بالتحديد
- تحديد الأخطاء: إذا أخطأوا في نطق كلمة واحدة في عبارة، نعرف أي منها
التحلل بخفة
إذا كان STT السحابي غير متاح (بدون إنترنت، مهلة API)، يستخدم النظام STT الجهاز وحده بسلاسة. الأطفال لا يرون خطأ — يحصلون فقط على ملاحظات أقل دقة. لا ينكسر التطبيق؛ فهو ينتقل فقط إلى وضع الجهاز فقط.
لماذا لا يستطيع المنافسون مجاراة هذا
تكرار هذا يتطلب:
- خبرة في بنية STT المحمول (إدارة البثين)
- تكامل مع Google Cloud مع تكييف الكلام
- بنية خلفية لمعالجة الصوت
- تقييم التشابه المعدل للشكلات العربية
- أنماط التحلل الناعم
- بيانات متعلمين تزيد عن 95,000+ لتأكيد الدقة
الأسئلة الشائعة
س: أي التعرف الصوتي يستخدم لتقييم طفلي؟
ج: STT السحابي مع توجيه السياق. STT الجهاز للأعمال الجارية فقط. ندمج كلاهما لتحديد الدقة النهائية.
س: لماذا يرى طفلي نصًا أخضر أثناء الحديث ولكن نتائج مختلفة بعده؟
ج: يعرض STT الجهاز نتائج جزئية، أقل دقة في الوقت الفعلي. تصل نتائج STT السحابي الأكثر دقة بعد انتهاء الحديث. كلا دورتين التغذية الراجعة لهما قيمة.
س: هل استخدام نظامي STT يكلف أكثر؟
ج: نعم، ولكن تحسين الدقة والتفاعل يبرر التكلفة. نقوم بتحسين باستخدام STT الجهاز أولاً وإرسال الصوت الكامل فقط للسحابة للتقييم.