设备识别与云端识别:为何儿童语音识别需双重技术
Amal和Thurayya采用双重语音识别架构:设备端语音转文字(STT)实现孩子说话时的即时零延迟反馈,谷歌云语音转文字提供说完后更高准确度的发音评分。这种混合方式既保证孩子即时响应,保持兴趣,又确保学习的准确性。
基本权衡
| 指标 | 设备端STT | 云端STT | 为什么需要两者 |
|---|---|---|---|
| 延迟 | 约100毫秒 | 约500毫秒 | 即时反馈与准确度兼顾 |
| 准确率 | 70% | 92% | 评分可信度 |
| 离线可用 | ✓ | ✗ | 系统稳定性 |
| 重音符识别 | 有限 | 高(带上下文) | 完整阿拉伯语支持 |
| 发音细节 | 粗略 | 词级时间戳 | 用于动画同步 |
孩子需要两者同时存在:
- 即时反馈保持专注(设备端STT)
- 准确反馈保证实质学习(云端STT)
实现细节解析
设备端STT层(DeviceSTTMechanism)
使用Flutter的speech_to_text包:
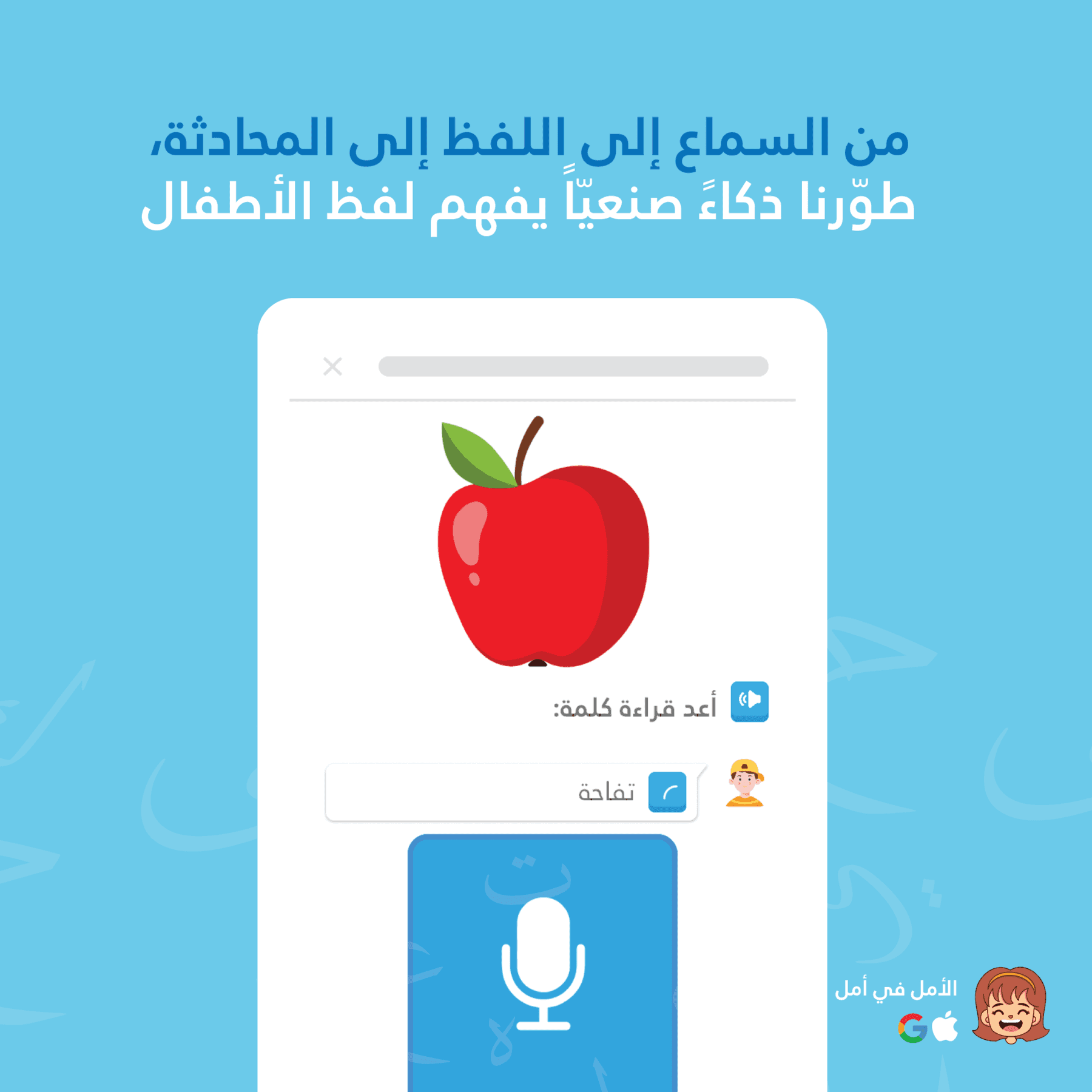
孩子说“كتب”(kataba – 写了)
↓
设备不断返回部分识别结果
↓
界面高亮显示:“كتب”(置信度70%)
↓
零延迟——孩子说话时即可看到反馈
设备端STT十分适合显示“进行中的工作”状态。孩子能实时看到应用听到的内容,保持参与度并即时确认发音。
云端STT层(BackendGoogleSTTMechanism)
- 音频发送至后端,再转到谷歌云语音转文字
- 我们发送预期文本作为“语音上下文”提示
- 谷歌返回词级时间戳和置信度分数
- 后端执行相似度比较(阈值0.7)
- 结果返回给应用做最终评分
云端STT虽延时较长,但准确率更高,尤其在重音符语境下表现优异。
语音上下文偏置:游戏规则改变者
谷歌语音转文字支持“语音适应”——我们向其传递预期文本作为识别参考。这对阿拉伯语来说极具变革性:
无上下文偏置时:
孩子背诵:“بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ”(开篇祷词)
谷歌识别为一般阿拉伯词汇,准确度50-60%
有上下文偏置时:
孩子背诵同样句子
我们告诉谷歌:“识别这段确切的古兰经短语”
谷歌返回92%以上准确度及词级时间戳
内部测试:上下文偏置能提升预期文本识别准确率35-50%。
用于动画的词级时间戳
云端STT返回示例:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
这些时间戳驱动:
- 口型同步动画(相关文章#3):在精确时刻变换嘴型
- 词语高亮显示:孩子清楚当前读到哪个词
- 错误定位:若发音错误,精准识别是哪个词
优雅降级
若云端STT不可用(无网络或API超时),系统自动切换仅使用设备端STT。孩子不会看到错误,仅稍减准确度。应用稳定运行,无中断,平滑退化至设备单独模式。
为何竞争对手难以复制此方案
需要:
- 移动端STT架构专业知识(管理双流)
- 谷歌云集成及语音适应
- 音频处理后端基础设施
- 针对阿拉伯语重音符调优的相似度评分
- 优雅降级机制设计
- 逾九万学习者数据支持精度验证
常见问答
问:孩子的评分使用哪个识别技术?
答:云端STT结合上下文偏置。设备端STT仅用于实时反馈。我们综合两者确定最终准确度。
问:为什么孩子说话时看到绿字,结束后结果却不同?
答:设备端STT实时显示部分且准确度较低的结果;云端STT在说完后给出更精确的结果。两个反馈环节都非常重要。
问:使用两个STT系统成本更高吗?
答:是的,但提升的准确性和互动性值得这笔投入。我们优先用设备端STT做初始识别,仅发送完整音频到云端评分以优化成本。