Device STT vs Cloud STT: Perché usiamo entrambi per il riconoscimento vocale dei bambini
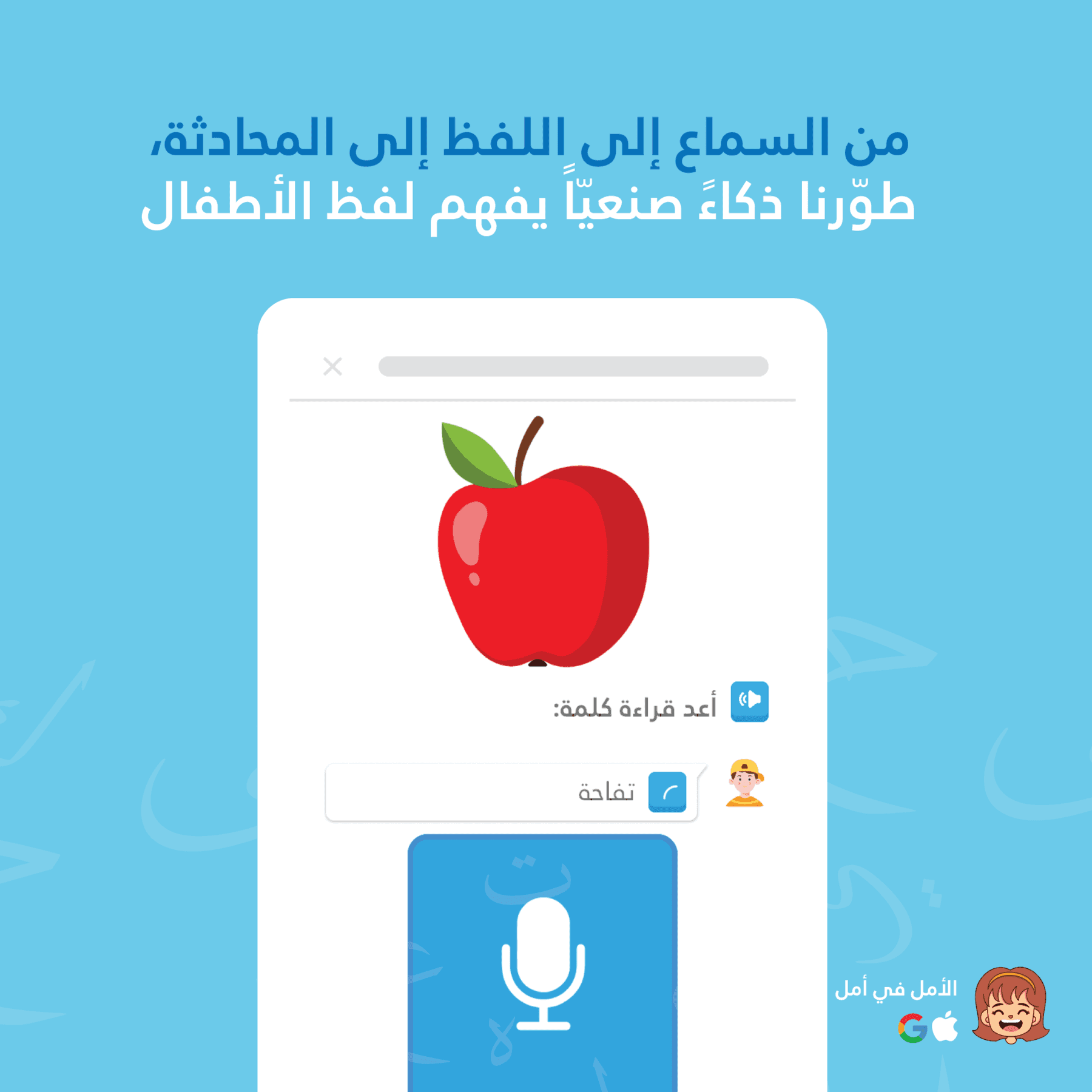
Amal e Thurayya utilizzano un'architettura di riconoscimento vocale doppia: STT on-device per un feedback istantaneo e senza latenza mentre il bambino parla, e Google Cloud Speech-to-Text per una valutazione della pronuncia più accurata al termine dell'esercizio. Questo approccio ibrido offre ai bambini la reattività immediata necessaria per mantenere il coinvolgimento, garantendo allo stesso tempo precisione per un apprendimento significativo.
Il compromesso fondamentale
| Metrica | Device STT | Cloud STT | Perché entrambi |
|---|---|---|---|
| Latenza | ~100ms | ~500ms | Feedback istantaneo + precisione |
| Precisione | 70% | 92% | Valutazione attendibile |
| Offline | ✓ | ✗ | Resilienza |
| Consapevolezza diacritica | Limitata | Alta (con contesto) | Supporto completo per l'arabo |
| Dettaglio pronuncia | Grezz | Timestamp per parola | Marche vocali per animazioni |
Il bambino ha bisogno di entrambi contemporaneamente:
- Il feedback istantaneo lo mantiene coinvolto (device STT)
- Il feedback preciso garantisce un vero apprendimento (cloud STT)
Approfondimento sull’implementazione
Layer Device STT (DeviceSTTMechanism) usa il pacchetto Flutter speech_to_text:
Bambino pronuncia "كتب" (kataba – scrisse)
↓
[Device trasmette risultati parziali]
↓
Interfaccia mostra evidenziazione verde: "كتب" (70% di sicurezza)
↓
[Latenza zero – il bambino vede il feedback durante il parlato]
Device STT è ideale per visualizzare il "lavoro in corso". I bambini vedono in tempo reale cosa riconosce l’app, mantenendo il coinvolgimento e confermando immediatamente l’input vocale.
Layer Cloud STT (BackendGoogleSTTMechanism):
- L’audio viene inviato al backend → Google Cloud Speech-to-Text
- Mandiamo il testo previsto come “contesto di parlato” per guida al riconoscimento
- Google restituisce timestamp a livello di parola e punteggi di confidenza
- Il backend confronta la similarità (soglia 0.7)
- Il risultato finale viene inviato all’app per la valutazione di punteggio
Cloud STT è più lento, ma molto più accurato, soprattutto grazie al supporto contestuale dei segni diacritici.
Bias del contesto vocale: la vera svolta
Google Speech-to-Text offre l’adattamento vocale, cioè possiamo inviare il testo atteso come hint di riconoscimento. Questo è fondamentale per l’arabo:
Senza bias contestuale:
Il bambino recita: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ" (Basmala – la preghiera iniziale)
Google comprende parole arabe generiche con precisione intorno al 50-60%
Con bias contestuale:
Il bambino recita: "بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِيمِ"
Indichiamo a Google: “Ascolta questa precisa frase coranica”
Google restituisce oltre il 92% di precisione con i timestamp specifici per parola
Benchmark interni: il bias contestuale migliora la precisione del riconoscimento dal 35 al 50% per i testi attesi.
Timestamp a livello di parola per le marche vocali
Cloud STT restituisce dati come:
{
"results": [
{
"word": "كتب",
"start_time": 0.2,
"end_time": 0.8,
"confidence": 0.94
}
]
}
Questi timestamp permettono:
- Animazioni di labbra sincronizzate (blog #3): cambi di posizione delle bocca in momenti precisi
- Evidenziazione parola per parola: il bambino vede esattamente su quale parola è
- Individuazione accurata degli errori: se sbaglia una parola in una frase, sappiamo quale
Degrado graduale
Se cloud STT non è disponibile (manca internet o timeout API), il sistema usa solo device STT. I bambini non vedono errori, ma ricevono un feedback leggermente meno preciso. L’app resta funzionante, ritornando semplicemente alla modalità solo device.
Perché i concorrenti non possono replicare tutto ciò
Per ottenere risultati simili servono:
- Esperienza nell’architettura mobile STT (gestione flussi doppi)
- Integrazione con Google Cloud e adattamento vocale
- Infrastruttura backend per elaborazione audio
- Scoring di similarità ottimizzato per diacritici arabi
- Procedure di degrado elegante
- Dataset di 95.000+ studenti per validazione della precisione
FAQ
Q: Quale riconoscimento vocale influenza il punteggio di mio figlio?
A: Il punteggio finale si basa su Cloud STT con bias contestuale. Device STT serve solo per feedback in tempo reale.
Q: Perché mio figlio vede testo verde durante il parlato ma risultati diversi dopo?
A: Device STT mostra risultati parziali meno accurati in tempo reale, Cloud STT consegna risultati più precisi dopo la pronuncia. Entrambi i feedback sono importanti.
Q: Usare due sistemi STT costa di più?
A: Sì, ma i miglioramenti in precisione e coinvolgimento giustificano i costi. Ottimizziamo usando device STT prima e inviamo l’audio completo al cloud solo per il punteggio.