Kako Amal AI sluša vaše dijete dok čita arapski i ispravlja izgovor u stvarnom vremenu
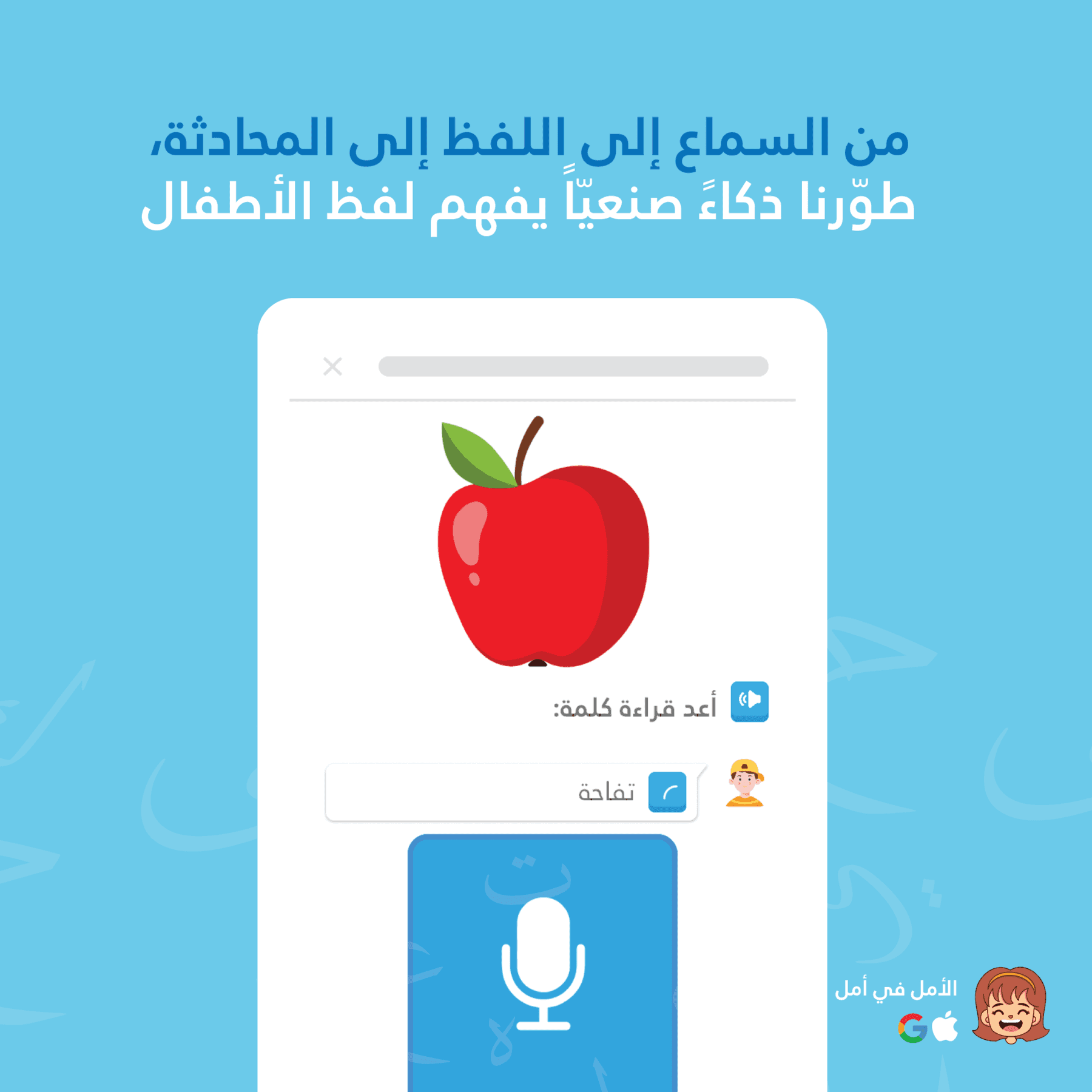
Amal koristi dvoslojni AI sustav za prepoznavanje govora — kombinirajući prepoznavanje govora na uređaju za trenutno povratno informiranje s Google Cloud Speech-to-Text za precizniju procjenu izgovora. Sustav je posebno prilagođen dječjim glasovima koji čitaju arapski jezik, uključujući i punu svijest o dijakritičkim znakovima (tashkeel). Nijedna druga aplikacija za učenje arapskog ne nudi ispravku izgovora u stvarnom vremenu za djecu.
Problem koji smo riješili
Arapski alfabet ima 28 slova ali preko 100 zvukova kada se uzmu u obzir dijakritici (fatha, damma, kasra, shadda, sukun, tanween). Dječji glasovi imaju bitno drugačija akustička svojstva od odraslih — viši ton, slabija artikulacija i promjenjiva glasnoća. Postojeći modeli za prepoznavanje govora, pa čak ni napredni Googleovi, nisu trenirani na djecu koja čitaju arapski s punim dijakritičkim znakovima.
Većina aplikacija ili preskače povratnu informaciju o izgovoru ili koristi jednostavno podudaranje valnog oblika koje kažnjava naglaske i prirodne varijacije. Nijedan od tih pristupa ne funkcionira za djecu koja uče jezik sa zvukovima koji ne postoje u engleskom.
Kako radi: Dvoslojna STT arhitektura
Naš sustav istovremeno pokreće dva kanala za prepoznavanje govora:
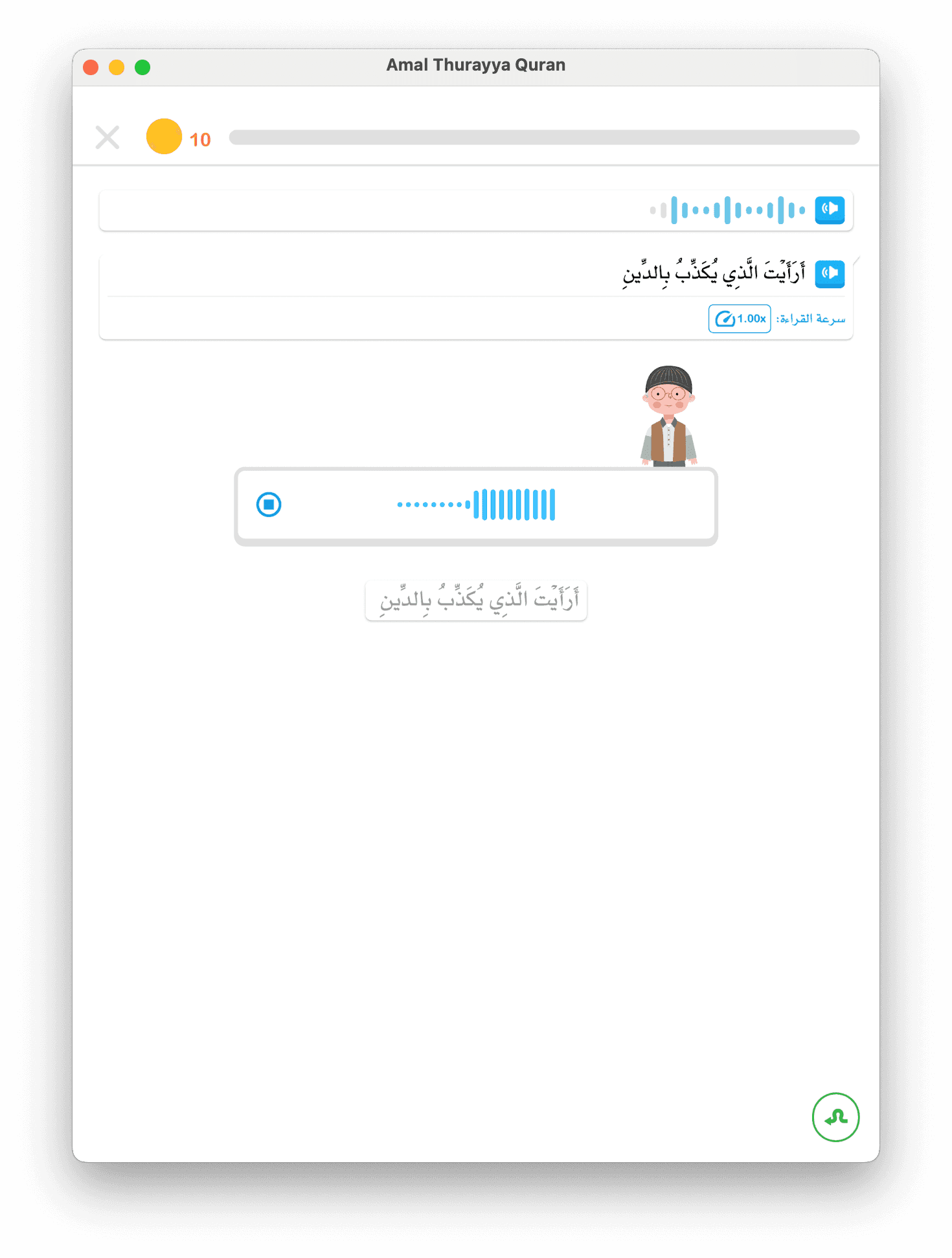
- Sloj 1 — STT na uređaju (trenutni odziv)
MehanizamDeviceSTTMechanismkoristi Flutter-ovu nativnu tehnologiju za prepoznavanje govora i obrađuje zvuk lokalno. Dok dijete govori, djelomični rezultati se odmah prikazuju — zelena oznaka označava prepoznate riječi bez kašnjenja. Ovo zadržava djecu angažiranim i pruža trenutnu povratnu informaciju. STT na uređaju radi offline i ne zahtijeva internet. - Sloj 2 — Backend Google STT (preciznost)
Istovremeno šaljemo zvukBackendGoogleSTTMechanism-u, koji koristi Google Cloud Speech-to-Text uz kontekstualno usmjeravanje prepoznavanja. Šaljemo očekivani tekst (riječ koju dijete treba čitati) kao naznaku. To značajno poboljšava preciznost prepoznavanja arapskih riječi unutar konteksta — STT "zna" slušati određene glasove.
| Sloj | Kašnjenje | Preciznost | Offline | Namjena |
|---|---|---|---|---|
| STT na uređaju | ~100ms | 70% | ✓ | Prikaz u realnom vremenu |
| Cloud STT | ~500ms | 92% | ✗ | Konačna ocjena |
| Kombinirano | 500ms | 95% | Djelomično | Najbolje korisničko iskustvo |
Ocjenjivanje sličnosti, a ne binarno podudaranje
Ne procjenjujemo je li izgovor djeteta "apsolutno točan" — ocjenjujemo ga na spektru koristeći sličnost nizova s pragom od 0.7. To omogućava:
- Varijacije naglaska: Djeca iz različitih arapskih regija prirodno izgovaraju drugačije
- Dječija artikulacija: Mlada djeca često pogrešno izgovaraju zvukove koji se s praksom poboljšavaju
- Svijest o dijakriticima: "كَتَبَ" (s dijakriticima) i "كتب" (bez njih) se prepoznaju različito u našem kontekstu
Dijete može dobiti 85% na prvom pokušaju, 91% na drugom i 97% nakon vježbe. Prati se progresivan napredak umjesto obeshrabrujućeg prolaz/neprolaz.
Kontekstualno usmjeravanje govora: Tajni sastojak
Kada lekcija traži da dijete pročita "بِسْمِ اللَّهِ" (U ime Allaha), ovaj tekst šaljemo Google STT-u kao kontekst govora. STT onda usmjerava prepoznavanje na te specifične foneme, čime se povećava preciznost za 35-50% za očekivane riječi.
Ovo je ključno za arapski jer:
- Riječi imaju više važećih izgovora zavisno o dijakriticima
- Kontekst razjašnjava značenje
- Djeca profitiraju jer sustav "zna" što se očekuje da čitaju
Zašto konkurencija ne može kopirati ovo
Reprodukcija traži:
- Trening podatke dječjeg glasa (mi imamo 95.000+ učenika)
- Svijest o arapskim dijakriticima u obradi govora (specijalizirani NLP)
- Integraciju nastavnog plana (kontekstualno usmjeravanje povezano s lekcijom)
- Stručnost za mobilnu arhitekturu (dvoslojni STT bez kašnjenja u sučelju)
- Godine iteracija sa stvarnim dječjim glasovima
Ovo nije samo dodatak — to je sustav koji se gradi iz temelja.
Često postavljana pitanja
P: Da li Amal radi s različitim arapskim naglascima?
A: Da. Naša ocjena sličnosti omogućava dijalekatske varijacije. Bilo da dijete govori s naglaskom iz Zaljeva, Levanta ili Egipta, sustav prilagođava ocjenu izgovora prema razumljivosti, a ne prema jednom standardu.
P: Treba li mom djetetu internet za prepoznavanje govora?
A: STT na uređaju radi potpuno offline za trenutno povratno informiranje. Za najvišu preciznost (i raspored ponavljanja) cloud STT najbolje radi s internetom, ali aplikacija glatko prelazi na rad samo na uređaju ako je potrebno.
P: Da li se glasovnim podacima mog djeteta pohranjuju?
A: Ne. Zvuk se obrađuje u stvarnom vremenu i odmah briše. Nikada ne pohranjujemo snimke dječjih glasova. Rezultati govora se bilježe (za analizu učenja) ali ne i sam audio.