আরবি শব্দ শেখানোর জন্য আমরা কেন লিপ-সিঙ্ক অ্যানিমেশন সিস্টেম তৈরি করেছি
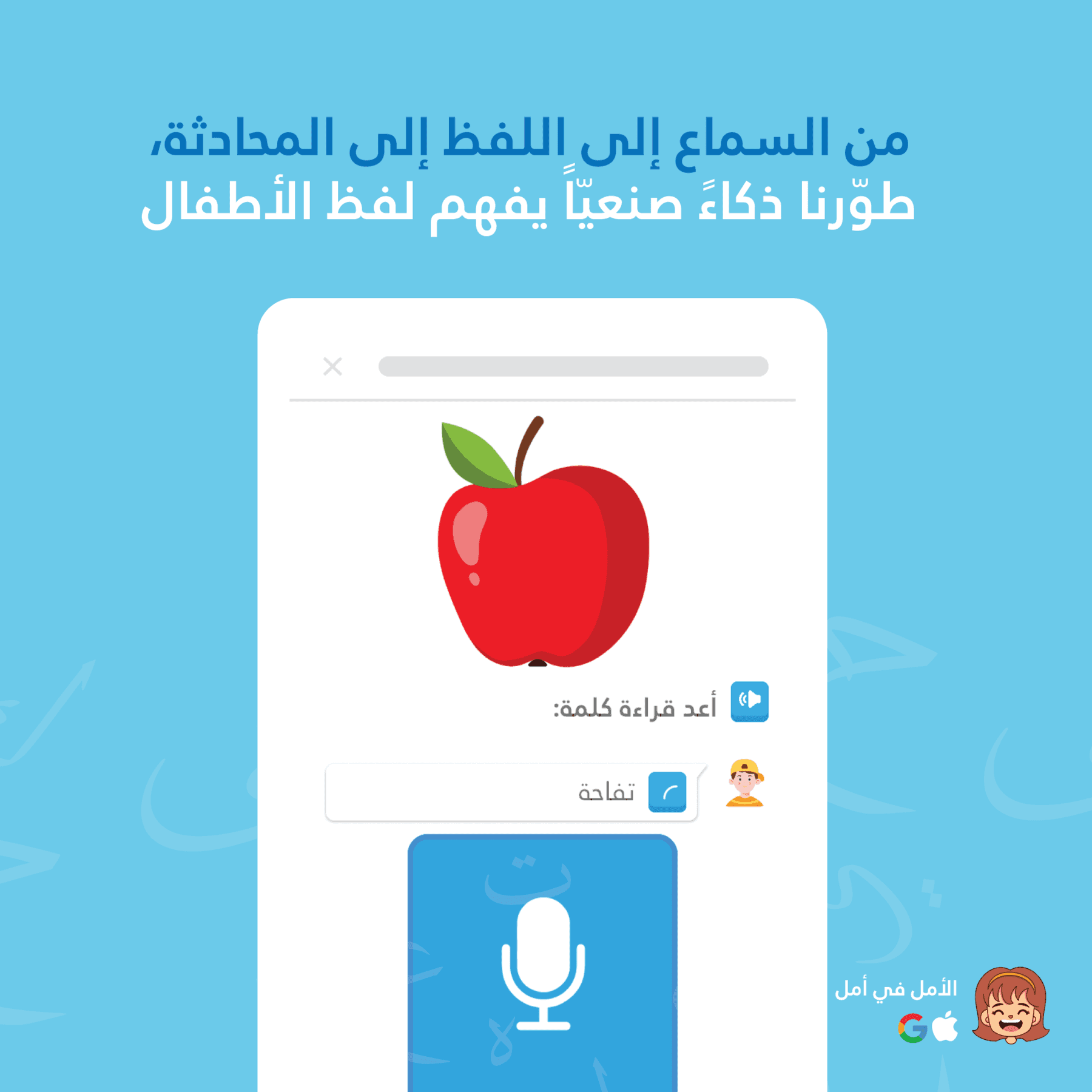
Amal Rive দ্বারা চালিত লিপ-সিঙ্ক অ্যানিমেশন ব্যবহার করে যা শিশুদের প্রতিটি আরবি শব্দ ঠিক কীভাবে গঠন করতে হয় তা দেখায় — চরিত্রের মুখ ধ্বনির সঙ্গে সিঙ্কে চলে। এই ভিজ্যুয়াল-ফোনেটিক পদ্ধতি শিশুদের স্বতঃস্ফূর্তভাবে উচ্চারণ শিখতে সাহায্য করে, বিশেষত এমন শব্দগুলোর জন্য যেগুলো ইংরেজিতে নেই (যেমন: ع, خ, غ, ح)।
সমস্যাটি: আরবিতে রয়েছে এমন শব্দ যা ইংরেজিতে নেই
আরবি ধ্বনিমালা অন্তর্ভুক্ত:
- ফ্যারিঞ্জিয়াল ব্যঞ্জনবর্ণ (ع, ح): গলায় গভীরভাবে উৎপন্ন, ইংরেজিতে সমতুল্য নেই
- উভুলার ব্যঞ্জনবর্ণ (ق, خ, غ): মুখের পেছনে উৎপন্ন
- এমফ্যাটিক ব্যঞ্জনবর্ণ (ص, ض, ط, ظ): জিহ্বা পিছনে সরিয়ে উচ্চারিত
শিশুরা শুধুমাত্র টেক্সট থেকে এই শব্দগুলি শিখতে পারে না—তাদের মুখের অবস্থান দেখতে হয়। প্রথাগত পদ্ধতি: শিক্ষক ব্যক্তিগতভাবে দেখান। আমাদের পদ্ধতি: একটি AI চরিত্র স্ক্রীনে দেখায়, ধৈর্যশীল ও সর্বদা উপলব্ধ।
লিপ-সিঙ্ক সিস্টেম কীভাবে কাজ করে
Rive অ্যানিমেশন ইঞ্জিন
Rive (যা আগেও Flare নামে পরিচিত) একটি 2D অ্যানিমেশন সিস্টেম যা স্টেট মেশিন সাপোর্ট করে। আমরা এটি ব্যবহার করি কারণ:
- স্টেট মেশিনগুলো সাহায্য করে মসৃণ ট্রানজিশনের জন্য idle → speaking → error → celebration
- রানটাইমে মুখের অবস্থান প্রোগ্রাম্যাটিক্যালি পরিবর্তন করা যায়, পূর্ব-রেন্ডার করা সিকোয়েন্স না চালিয়ে
- একই .riv ফাইলে সব অ্যানিমেশন স্টেট থাকে (হাজারো স্প্রাইট ফ্রেমের বদলে)
- GPU ত্বরিত, মাঝারি সামর্থ্যের ডিভাইসে 60fps
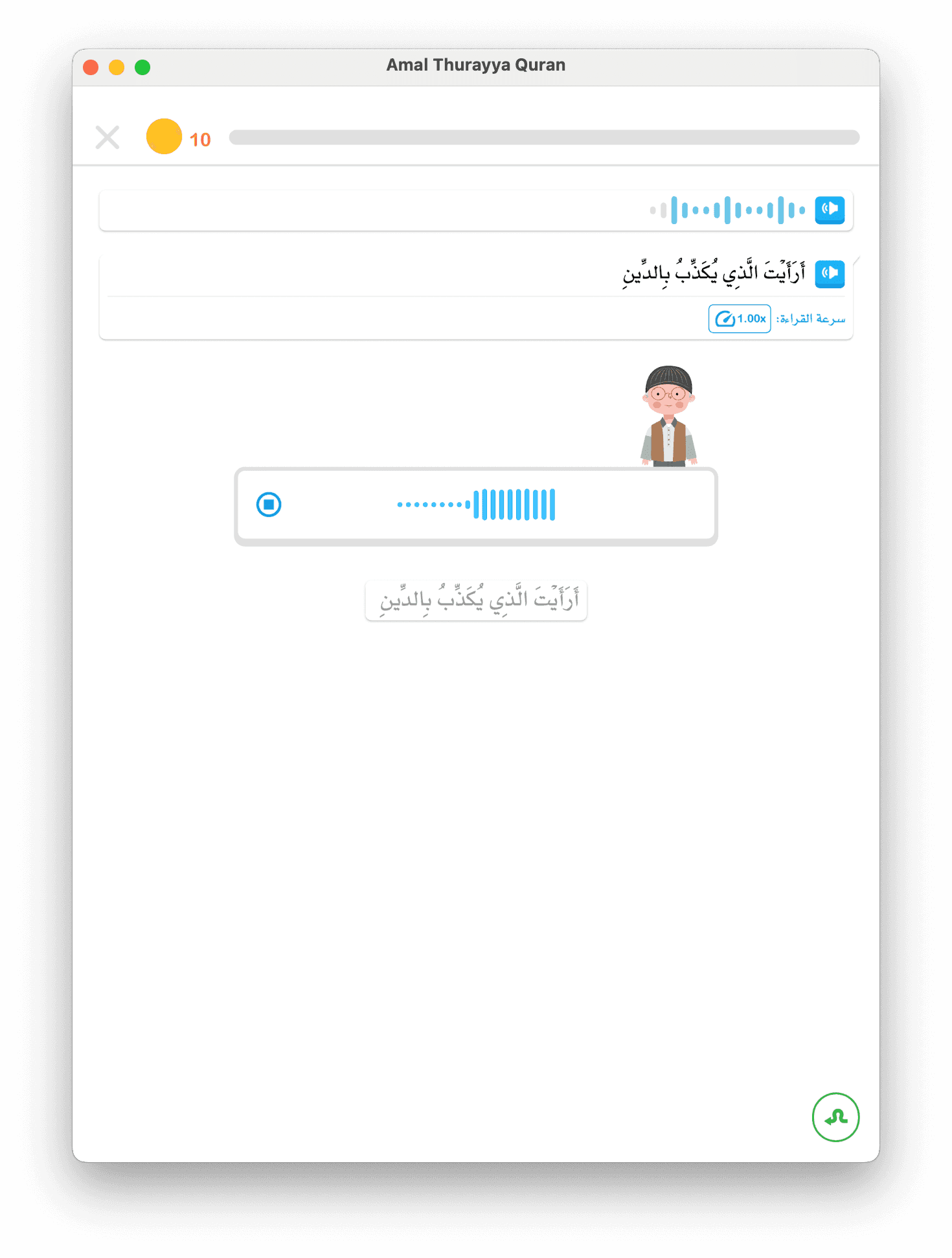
স্পীচ মার্কস পিপলাইন
- টেক্সট-টু-স্পীচ (TTS) ব্যবহার করে "أَنَا" (আমি) শব্দের অডিও তৈরি
- TTS দেয় স্পীচ মার্কস — প্রতিটি ধ্বনির জন্য নির্দিষ্ট টাইমস্ট্যাম্প
- আমাদের
lip_sync_avatar.jsonফাইলে ধ্বনি ও রাইভ মুখের অবস্থানের ম্যাপিং LipSyncControllerস্টেট মেশিনকে প্লেব্যাকের সঙ্গে সিঙ্ক করে- শিশু চরিত্রের মুখকে সঠিক অবস্থানে দেখতে পায় যখন শব্দ শোনে
TTS Audio + Speech Marks
↓
[Extract Phoneme Timing]
↓
[Map to Rive States]
↓
[Animate Character Mouth]
↓
[Child Sees Mouth Position]
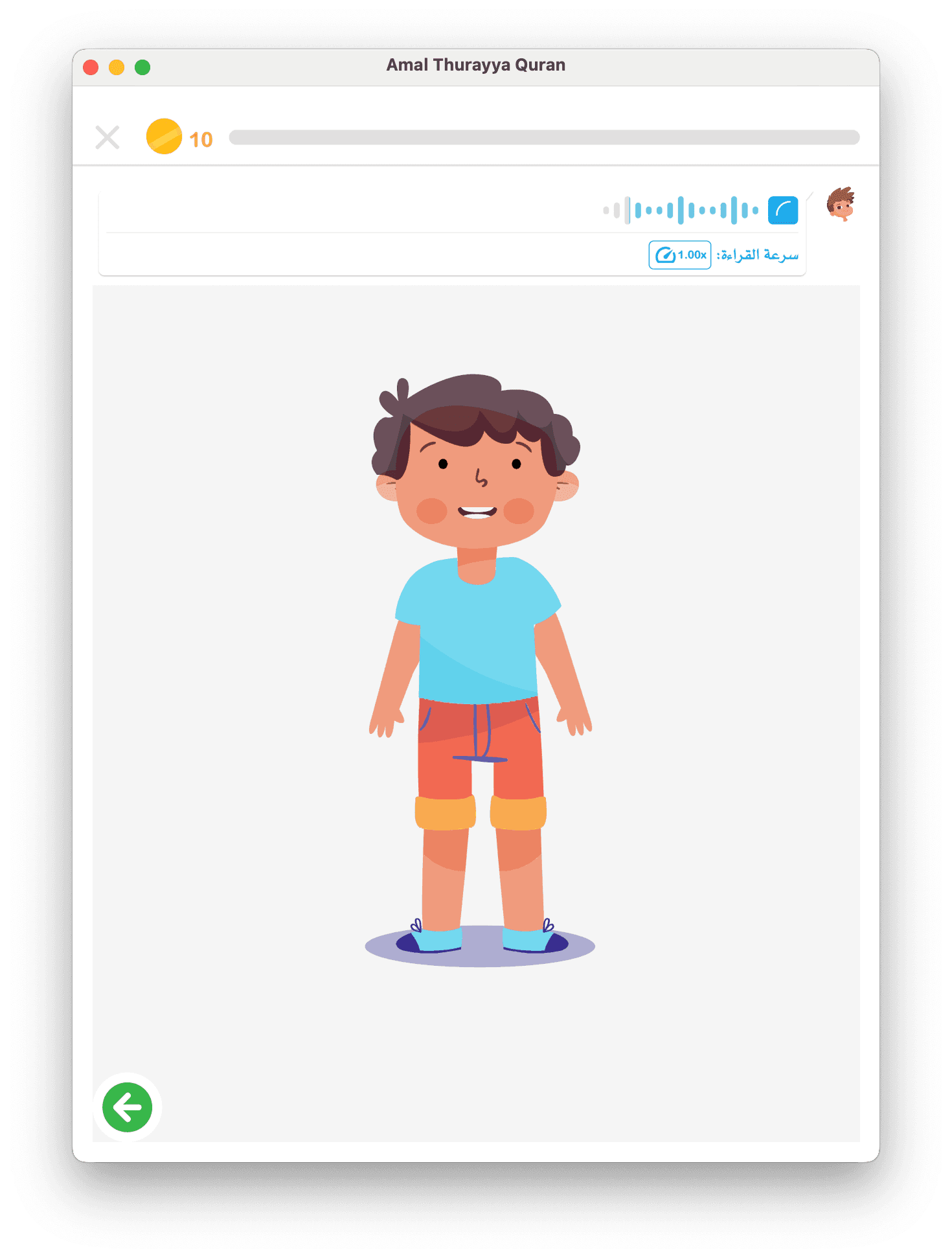
বিভিন্ন চরিত্রৰ বৈচিত্র্য
- মূল Amal চরিত্র যা ফুল-বডি এবং শুধু মুখের ভেরিয়েন্টে আসে
- বন্ধুত্বপূর্ণ সহায়ক চরিত্র সংযোজন এবং আকর্ষণের জন্য
- কাস্টমাইজযোগ্য এভারটার: শিশু মাথার আকৃতি, পোশাক, রঙ-আনুষঙ্গিক বাছাই করে
- অনুভূতি প্রকাশের অবস্থা: idle, কথা বলা, ত্রুটি (উৎসাহদায়ক), সাফল্য (প্রশংসা)
শিশুরা যখন তাদের পছন্দমতো চরিত্র কাস্টমাইজ করে, সেই ব্যক্তিগত এভারটার পুরো অ্যাপ জুড়ে তাদের শেখায় — যা মানসিক সংযোগ তৈরি করে।
কেন Rive ব্যবহার করি (Lottie বা স্প্রাইট শীট নয়)
| পদ্ধতি | স্টেট মেশিন | রানটাইম কন্ট্রোল | ফাইল সাইজ | পারফরমেন্স | খরচ |
|---|---|---|---|---|---|
| Rive | ✓ | ✓ | 1.2 এমবি | 60fps | ইঞ্জিনিয়ারিং সময় |
| Lottie | ✗ | আংশিক | 2-3 এমবি | 30fps | অ্যানিমেশন সময় |
| স্প্রাইট | ✗ | ম্যানুয়াল | ৫০+ এমবি | 60fps | অ্যাসেট সংরক্ষণ |
| ভিডিও | প্রযোজ্য নয় | ✗ | ১০০+ এমবি | পরিবর্তনশীল | হোস্টিং খরচ |
Rive জিতে যায় কারণ আমাদের প্রোগ্রাম্যাটিক নিয়ন্ত্রণ, স্টেট ট্রানজিশন এবং ছোট ফাইল সাইজ দরকার, যা ৯৫,০০০+ শিশুদের জন্য মোবাইল অ্যাপে উপযোগী।
শিক্ষাগত প্রভাব
গবেষণা দেখিয়েছে ভিজ্যুয়াল-ফোনেটিক পদ্ধতি (মুখের অবস্থা দেখানো যখন শব্দ শোনা হয়) উচ্চারণ শেখার গতি বাড়ায়। আমাদের অভ্যন্তরীণ তথ্য:
- লিপ-সিঙ্ক দেখানো শিশু ৪০% দ্রুত উচ্চারণ শেখে
- দৃশ্যমান প্রতিক্রিয়ায় উচ্চারণের নির্ভুলতা তিনগুণ এগিয়ে যায়
- বিশেষ করে দেশের বাইরে থাকা বাচ্চাদের জন্য কার্যকর যারা বাড়িতে আরবি কণ্ঠস্বর পায় না
কেন প্রতিযোগীরা এই পদ্ধতি প্রদান করতে পারে না
এটি তৈরি করতে প্রয়োজন:
- ধ্বনিতত্ত্ব জ্ঞান (কোন মুখের অবস্থান কোন শব্দের জন্য)
- Rive অ্যানিমেশন দক্ষতা (স্টেট মেশিন ডিজাইন জটিল)
- TTS স্পীচ মার্কস ইন্টিগ্রেশন (সব সেবা দেয় না)
- মোবাইল অপ্টিমাইজেশন (৬০fps এ রেন্ডারিং)
- চরিত্র কাস্টমাইজেশন সিস্টেম (কম্পোনেন্ট ভিত্তিক এভারটার নির্মাণ)
প্রশ্নোত্তর
Q: আমার সন্তান কি অ্যানিমেশনের গতি সামঞ্জস্য করতে পারে?
A: হ্যাঁ। ধীর গতি কঠিন শব্দ শেখার জন্য ভালো; দ্রুত গতি উন্নত শিক্ষার্থীদের জন্য। অ্যাপ পারফরমেন্সের উপর ভিত্তি করে পরিবর্তিত হয়।
Q: সব অনুশীলনে কি লিপ-সিঙ্ক অ্যানিমেশন আছে?
A: বলুন-স্বর অনুশীলন ও উচ্চারণ অনুশীলনে পূর্ণ লিপ-সিঙ্ক থাকে। অন্য গেম বা পাজল অনুশীলনে চরিত্র উৎসাহ এবং পুরষ্কার দেয়ার অ্যানিমেশন দেখায়।
Q: কখন কখন চরিত্র ত্রুটি অ্যানিমেশন দেখায়?
A: উচ্চারণ ভুল সনাক্ত করলে চরিত্র কোমলভাবে “আবার চেষ্টা করি” ভঙ্গিতে দেখায়। এটা শাস্তি নয়, উৎসাহ — শিশু বার বার চেষ্টা করেই শেখে।